


GATE 2023 CSE Question Paper PDF is available here for download. IIT Kanpur conducted GATE 2023 CSE exam on February 4, 2023 in the Forenoon Session from 09:30 AM to 12:30 PM. According to the initial reaction of the student, GATE CSE 2023 question paper was reported to be easy to moderate in difficulty. There were 34 MCQs, 15 MSQs and 16 NATs in GATE 2023 CSE Question Paper. 10 questions are from the General Aptitude section and 55 questions are from Engineering Mathematics and Core Discipline.
GATE 2023 CSE Question Paper with Solutions PDF
| GATE 2023 CSE Question Paper with Solutions | Check Solutions |

We reached the station late, and missed the train.
View Solution
In this sentence, the correct word is “nearly.” The word “nearly” is used as an adverb to describe the action “missed the train.” It suggests that the action was almost completed, but just short of actually happening.
- (A) "near" is incorrect because "near" is a preposition or adjective, not an adverb.
- (C) "utterly" is incorrect because "utterly" means completely, which doesn't fit the context here.
- (D) "mostly" is incorrect as it implies a majority or predominant action, which doesn't align with the context of "almost" missing the train.
Thus, the correct answer is (B) "nearly." Quick Tip: When expressing something that was almost or very close to happening, "nearly" is the best choice.
Kind : _______ : : Often : Frequently
View Solution
This analogy is based on word meanings. The relationship between "Kind" and "Kindly" is that they are different forms of the same word. "Kind" is an adjective, and "Kindly" is an adverb derived from it. Similarly, the word "Frequently" is an adverb, and "Often" is the synonymous adjective form. Hence, "Kind : Kindly" follows the same structure as "Often : Frequently." Quick Tip: When solving analogies involving word meanings, focus on the grammatical forms (adjective, adverb, etc.) and their relationships.
A series of natural numbers \(F_1, F_2, F_3, F_4, F_5, F_6, F_7, \ldots\) obeys \(F_{n+1}=F_n+F_{n-1}\) for all integers \(n\ge 2\). If \(F_6=37\) and \(F_7=60\), then what is \(F_1\)?
View Solution
Step 1: Use the recurrence backward from the given terms.
From \(F_{n+1}=F_n+F_{n-1}\) with \(n=6\): \[ F_7=F_6+F_5 \Rightarrow 60=37+F_5 \Rightarrow F_5=23. \]
Step 2: Keep stepping back to find earlier terms.
\[ F_6=F_5+F_4 \Rightarrow 37=23+F_4 \Rightarrow F_4=14. \] \[ F_5=F_4+F_3 \Rightarrow 23=14+F_3 \Rightarrow F_3=9. \] \[ F_4=F_3+F_2 \Rightarrow 14=9+F_2 \Rightarrow F_2=5. \] \[ F_3=F_2+F_1 \Rightarrow 9=5+F_1 \Rightarrow F_1=4. \]
\[ \boxed{F_1=4} \] Quick Tip: For linear recurrences like \(F_{n+1}=F_n+F_{n-1}\), you can move \emph{backwards} just as reliably as forwards: solve each equation for the unknown earlier term and keep stepping back until you reach the required starting value.
Looking at the surface of a smooth 3-dimensional object from the outside, which one of the following options is TRUE?
View Solution
In a 3-dimensional object, the surface may have different geometries in different places. The surface can be concave in some areas (curved inward) and convex in others (curved outward). This means the surface is not necessarily one type everywhere, as shown by the option in (C).
- (A) is incorrect because the surface does not have to be concave everywhere.
- (B) is incorrect because a surface does not have to be convex everywhere.
- (D) is also incorrect, as the object can indeed have corners in certain geometric configurations (e.g., cubes).
Thus, the correct answer is (C), as the surface can be both concave and convex in different places. Quick Tip: In 3D geometry, a surface can exhibit both concave and convex properties at different locations.
The country of Zombieland is in distress since more than 75% of its working population is suffering from serious health issues. Studies conducted by competent health experts concluded that a complete lack of physical exercise among its working population was one of the leading causes of their health issues. As one of the measures to address the problem, the Government of Zombieland has decided to provide monetary incentives to those who ride bicycles to work.
Based only on the information provided above, which one of the following statements can be logically inferred with certainty?
View Solution
The information provided in the question clearly mentions that the health experts concluded a lack of physical exercise as a leading cause of health issues in the working population. The government has decided to provide incentives for riding bicycles, which suggests that the government views riding bicycles as a form of physical exercise. Therefore, option (D) is logically inferred with certainty.
Why not other options?
- (A) is incorrect because there is no certainty that all of the working population will ride bicycles to work; the decision is only to provide incentives.
- (B) is incorrect because while riding bicycles may contribute to physical exercise, it does not guarantee the resolution of all health issues.
- (C) is incorrect because the information does not specify that the health experts recommended making bicycle riding mandatory, only that they linked health issues to the lack of exercise. Quick Tip: In inference-based questions, focus on what can be directly concluded from the given facts, without making assumptions beyond the provided information.
Consider two functions of time \((t)\), \[ f(t) = 0.01t^2, g(t) = 4t \]
where \(0 < t < \infty\).
Now consider the following two statements:
(i) For some \(t > 0\), \(g(t) > f(t)\).
(ii) There exists a \(T\), such that \(f(t) > g(t)\) for all \(t > T\).
Which one of the following options is TRUE?
View Solution
Step 1: Compare \(f(t)\) and \(g(t)\).
We want to solve when \(f(t) > g(t)\) or \(g(t) > f(t)\). \[ f(t) = 0.01t^2, g(t) = 4t \]
So we compare: \[ 0.01t^2 vs. 4t \]
Step 2: Inequality setup.
Check when \(g(t) > f(t)\): \[ 4t > 0.01t^2 \Rightarrow 0.01t^2 - 4t < 0 \]
Factor: \[ 0.01t(t - 400) < 0 \]
Step 3: Range for inequality.
This inequality is true when \(0 < t < 400\).
Thus, for some positive \(t\) (specifically, \(t < 400\)), \(g(t) > f(t)\).
Hence, statement (i) is correct.
Step 4: Check for large \(t\).
As \(t \to \infty\), the quadratic term \(0.01t^2\) grows faster than the linear term \(4t\).
Thus, beyond \(t = 400\), \[ f(t) > g(t) \forall t > 400 \]
So, statement (ii) is also correct.
Step 5: Conclusion.
Both (i) and (ii) are true.
\[ \boxed{Both (i) and (ii) are correct.} \] Quick Tip: When comparing growth rates, linear functions dominate quadratics for small \(t\), but quadratics eventually dominate for large \(t\). Always check both small and large values.
Which one of the following sentence sequences creates a coherent narrative?
(i) Once on the terrace, on her way to her small room in the corner, she notices the man right away.
(ii) She begins to pant by the time she has climbed all the stairs.
(iii) Mina has bought vegetables and rice at the market, so her bags are heavy.
(iv) He was leaning against the parapet, watching the traffic below.
View Solution
Step 1: Establish the starting context.
Sentence (iii) sets the background: Mina is returning from the market with heavy bags. This logically precedes any movement or arrival \(\Rightarrow\) it should come first.
Step 2: Show movement toward the setting.
With heavy bags, she climbs upstairs and gets tired. Sentence (ii) (“she begins to pant… after all the stairs”) naturally follows (iii) as the consequence of carrying heavy bags.
Step 3: Arrival on the terrace.
After climbing, she reaches the terrace. Sentence (i) explicitly begins “Once on the terrace…” \(\Rightarrow\) it must come after (ii).
Step 4: Describe what she notices.
Sentence (iv) details the man she has noticed (“He was leaning against the parapet…”). This elaborates the object of noticing mentioned in (i), so (iv) follows (i).
\[ \boxed{(iii)\ \rightarrow\ (ii)\ \rightarrow\ (i)\ \rightarrow\ (iv)} \] Quick Tip: For ordering sentences, look for a natural timeline: \emph{background cause} \(\Rightarrow\) \emph{movement/process} \(\Rightarrow\) \emph{arrival/transition markers (“once…”, “then…”)} \(\Rightarrow\) \emph{observation or result}.
f(x) and g(y) are functions of x and y, respectively, and \( f(x) = g(y) \) for all real values of x and y. Which one of the following options is necessarily TRUE for all x and y?
View Solution
Since \( f(x) = g(y) \) for all real values of \( x \) and \( y \), this means that for any value of \( x \), the value of \( f(x) \) is equal to the value of \( g(y) \), implying that both functions must be constant to maintain equality across all values of \( x \) and \( y \). Thus, \( f(x) \) and \( g(y) \) must both be constants.
- (A) is incorrect because there is no necessity that \( f(x) = 0 \) and \( g(y) = 0 \) for all \( x \) and \( y \); both functions must just be constants.
- (C) is incorrect because the assumption that \( f(x) \) and \( g(y) \) are not constants contradicts the condition \( f(x) = g(y) \) for all \( x \) and \( y \).
- (D) is incorrect because \( f(x) + g(y) = f(x) - g(y) \) implies that \( g(y) \) must be 0, which is not necessary given the conditions.
Thus, the correct answer is (B): both \( f(x) \) and \( g(y) \) must be constants. Quick Tip: When two functions are equal for all real values of their variables, they must be constant to maintain the equality.
Which one of the options best describes the transformation of the 2-dimensional figure P to Q, and then to R, as shown?
View Solution
Looking at the transformations from figure P to Q and from Q to R:
- The transformation from P to Q involves rotating the figure by 90° in a clockwise direction. This indicates a clockwise rotation of the figure by 90° about an axis perpendicular to the plane of the figure. Therefore, Operation 1 is a clockwise rotation by 90°.
- The transformation from Q to R involves a reflection of the figure across a horizontal line. This matches with the second operation, which is a reflection along a horizontal line.
Thus, the correct choice is option (A). Quick Tip: When analyzing geometric transformations, carefully observe the relative orientation of the figure after each operation. A rotation changes the angle, while a reflection flips the figure across a line.
Consider the following statements regarding the front-end and back-end of a compiler.

S1: The front-end includes phases that are independent of the target hardware.
S2: The back-end includes phases that are specific to the target hardware.
S3: The back-end includes phases that are specific to the programming language used in the source code.
Identify the CORRECT option.
View Solution
Step 1: Understand the role of the front-end.
The front-end of a compiler performs lexical analysis, syntax analysis, and semantic analysis. These phases are independent of the target hardware. They depend only on the source programming language.
Thus, S1 is TRUE.
Step 2: Understand the role of the back-end.
The back-end deals with code generation, machine-specific optimization, and register allocation. These steps depend on the target hardware.
Thus, S2 is TRUE.
Step 3: Evaluate S3.
S3 states: "The back-end includes phases that are specific to the programming language used in the source code."
This is incorrect. Programming language-specific phases (lexical, syntax, semantic analysis) belong to the front-end, not the back-end.
Hence, S3 is FALSE.
Step 4: Conclusion.
From the above analysis, only S1 and S2 are TRUE.
\[ \boxed{Correct Option: (B) Only S1 and S2 are TRUE.} \] Quick Tip: Remember: Front-end is language-dependent but machine-independent, while Back-end is machine-dependent but language-independent.
Which one of the following sequences when stored in an array at locations \(A[1], \ldots, A[10]\) forms a max-heap?
View Solution
Step 1: Recall the max-heap property.
In a max-heap, each parent node must be greater than or equal to its children.
If the array is indexed from \(1\), then for any element at index \(i\): \[ Left child at 2i, Right child at 2i+1 \]
Step 2: Check option (B).
Array (B): \([23, 17, 14, 7, 13, 10, 1, 5, 6, 12]\)
- Root: \(A[1] = 23\) has children \(17, 14\) (both \(\leq 23\)). ✔
- \(A[2] = 17\) has children \(7, 13\) (both \(\leq 17\)). ✔
- \(A[3] = 14\) has children \(10, 1\) (both \(\leq 14\)). ✔
- \(A[4] = 7\) has children \(5, 6\) (both \(\leq 7\)). ✔
- \(A[5] = 13\) has children \(12\) only (and \(12 \leq 13\)). ✔
All parents satisfy the max-heap property.
Step 3: Eliminate other options.
- (A) fails because \(A[3]=10\) has child \(A[6]=14\), which is greater. ✘
- (C) fails because \(A[3]=14\) has child \(A[10]=15\), which is greater. ✘
- (D) fails because \(A[3]=17\) has child \(A[7]=16\) (okay), but \(A[2]=14\) has child \(A[5]=10\) (okay) — however, \(A[3]=17\) and \(A[2]=14\) comparison not relevant; still, structure violations occur deeper. ✘
Thus, only option (B) is a valid max-heap.
\[ \boxed{The sequence in (B) forms a max-heap.} \] Quick Tip: For heap questions, always check parent-child pairs using the index rules (\(2i\) and \(2i+1\)). If any child is larger than its parent, the max-heap property is violated.
Let SLLdel be a function that deletes a node in a singly-linked list given a pointer to the node and a pointer to the head of the list. Similarly, let DLLdel be another function that deletes a node in a doubly-linked list given a pointer to the node and a pointer to the head of the list. Let n denote the number of nodes in each of the linked lists. Which one of the following choices is TRUE about the worst-case time complexity of SLLdel and DLLdel?
View Solution
In the case of singly-linked lists (SLL), to delete a node, we need to traverse the list from the head to the node we want to delete. This requires us to go through the entire list in the worst case, which results in a time complexity of \( O(n) \). Therefore, the time complexity of SLLdel is \( O(n) \).
In the case of doubly-linked lists (DLL), since each node contains a pointer to both the next and the previous node, we do not need to traverse the list to find the node to delete. We can directly access the previous and next nodes of the node to be deleted, making the deletion process occur in constant time. Therefore, the time complexity of DLLdel is \( O(1) \).
Thus, the correct answer is (D): SLLdel is \( O(n) \) and DLLdel is \( O(1) \). Quick Tip: In a singly-linked list, we must traverse the list to delete a node, resulting in a time complexity of \( O(n) \), while in a doubly-linked list, node deletion can be done in constant time \( O(1) \).
Consider the Deterministic Finite-state Automaton (DFA) A shown below. The DFA runs on the alphabet {0, 1}, and has the set of states {s, p, q, r}, with s being the start state and p being the only final state.

Which one of the following regular expressions correctly describes the language accepted by A?
View Solution
The DFA has the following transitions:
- State \( s \) is the start state.
- On input \( 1 \), the DFA moves to state \( p \).
- From state \( p \), on input \( 1 \), it moves to state \( q \), and on input \( 0 \), it moves to state \( r \).
- From state \( q \), on input \( 0 \), it goes to state \( r \), and on input \( 1 \), it goes to state \( p \).
- From state \( r \), on input \( 0 \), it moves to state \( s \), and on input \( 1 \), it moves to state \( p \).
- The final state is \( p \).
To describe the language accepted by the DFA, we observe:
- Starting from state \( s \), the first \( 1 \) moves the automaton to state \( p \).
- After that, the DFA can accept zero or more repetitions of either \( 0 \) or \( 11 \), which leads to the regular expression \( 1(0 + 11)^* \).
Thus, the correct answer is option (C).
Quick Tip: When converting DFA to regular expression, first trace all possible transitions and determine the patterns that the DFA accepts. Then form the regular expression based on the observed transitions.
The Lucas sequence \(L_n\) is defined by the recurrence relation: \[ L_n = L_{n-1} + L_{n-2}, for n \geq 3, \]
with \(L_1 = 1\) and \(L_2 = 3\).
Which one of the options given is TRUE?
View Solution
Step 1: Characteristic equation.
The recurrence relation is: \[ L_n = L_{n-1} + L_{n-2} \]
Its characteristic polynomial is: \[ x^2 - x - 1 = 0 \]
Step 2: Solve for roots.
The roots are: \[ \alpha = \frac{1+\sqrt{5}}{2}, \beta = \frac{1-\sqrt{5}}{2} \]
Step 3: General solution form.
The solution has the form: \[ L_n = A\alpha^n + B\beta^n \]
Step 4: Use initial conditions.
For \(n=1\): \[ L_1 = 1 = A\alpha + B\beta \]
For \(n=2\): \[ L_2 = 3 = A\alpha^2 + B\beta^2 \]
Step 5: Known property of Lucas sequence.
The Lucas sequence is well-known to satisfy: \[ L_n = \alpha^n + \beta^n \]
where \(\alpha, \beta\) are the roots of \(x^2 - x - 1 = 0\).
Step 6: Verification.
Check \(n=1\): \[ L_1 = \alpha + \beta = \frac{1+\sqrt{5}}{2} + \frac{1-\sqrt{5}}{2} = 1 \]
Check \(n=2\): \[ L_2 = \alpha^2 + \beta^2 = (\alpha+\beta)^2 - 2\alpha\beta = 1^2 - 2(-1) = 3 \]
This matches perfectly.
\[ \boxed{L_n = \left(\frac{1+\sqrt{5}}{2}\right)^n + \left(\frac{1-\sqrt{5}}{2}\right)^n} \] Quick Tip: The Lucas sequence is closely related to the Fibonacci sequence. While Fibonacci numbers use \(\frac{\alpha^n - \beta^n}{\alpha - \beta}\), the Lucas numbers use \(\alpha^n + \beta^n\).
Which one of the options given below refers to the degree (or arity) of a relation in relational database systems?
View Solution
Step 1: Recall the concept of degree (arity).
In relational database systems, the \emph{degree (or arity) of a relation is defined as the number of attributes (columns) in the relation schema.
Step 2: Clarify the difference with cardinality.
- The \emph{cardinality of a relation refers to the number of tuples (rows) it contains.
- The \emph{degree is independent of the number of tuples; it only depends on how many attributes are defined in the schema.
Step 3: Eliminate wrong options.
- (B) refers to the number of tuples \(\Rightarrow\) cardinality, not degree. ✘
- (C) “number of entries” is vague and not a standard DBMS term. ✘
- (D) “number of distinct domains” is unrelated to degree; domains define allowable values. ✘
Hence, option (A) is correct.
\[ \boxed{Degree (arity) of a relation = Number of attributes in its schema.} \] Quick Tip: Remember: In DBMS — Degree = Number of attributes (columns), Cardinality = Number of tuples (rows). This distinction often appears in exams.
Suppose two hosts are connected by a point-to-point link and they are configured to use Stop-and-Wait protocol for reliable data transfer. Identify in which one of the following scenarios, the utilization of the link is the lowest.
View Solution
In the Stop-and-Wait protocol, the sender sends a frame and waits for an acknowledgment before sending the next frame. The link utilization in Stop-and-Wait is impacted by both the round-trip time (RTT) and the transmission rate. If the link length is longer, the round-trip time increases, and if the transmission rate is higher, the time to send each frame decreases. However, the Stop-and-Wait protocol is limited by the time spent waiting for acknowledgments.
When the link length is longer, the round-trip time increases, and even with a higher transmission rate, the time spent waiting for an acknowledgment can still dominate the utilization. This leads to lower link utilization, as the sender spends more time waiting than actually sending data. Therefore, in this case, the utilization is the lowest when the link length is longer and the transmission rate is higher (option B).
Thus, the correct answer is (B): Longer link length and higher transmission rate. Quick Tip: In Stop-and-Wait, longer link lengths and higher transmission rates can lead to lower utilization due to the increased round-trip time.
Let \[ A = \begin{bmatrix} 1 & 2 & 3 & 4
4 & 1 & 2 & 3
3 & 4 & 1 & 2
2 & 3 & 4 & 1 \end{bmatrix} and B = \begin{bmatrix} 3 & 4 & 1 & 2
4 & 1 & 2 & 3
1 & 2 & 3 & 4
2 & 3 & 4 & 1 \end{bmatrix} \]
Let det(A) and det(B) denote the determinants of the matrices A and B, respectively.
Which one of the options given below is TRUE?
View Solution
The matrices \( A \) and \( B \) are related by a row swap operation. To find the determinant relationship between \( A \) and \( B \), observe the following:
- The matrix \( B \) is obtained by permuting the rows of matrix \( A \), which changes the sign of the determinant.
- Since \( B \) is a row permutation of \( A \), the determinant of \( B \) is the negative of the determinant of \( A \). Hence, \( det(B) = -det(A) \).
Thus, the correct answer is option (B).
Quick Tip: When two matrices are related by a row or column swap, their determinants are negatives of each other.
Consider the following definition of a lexical token \texttt{id for an identifier in a programming language, using extended regular expressions:
\[ letter \;\;\rightarrow\;\; [A\!-\!Za\!-\!z] \] \[ digit \;\;\rightarrow\;\; [0\!-\!9] \] \[ id \;\;\rightarrow\;\; letter (letter | digit)^* \]

Which one of the following Non-deterministic Finite-state Automata with \(\epsilon\)-transitions accepts the set of valid identifiers? (A double-circle denotes a final state).
View Solution
Step 1: Understand the regular expression.
The rule for a valid identifier is: \[ id = letter (letter | digit)^* \]
This means:
- The first character must be a letter.
- The subsequent characters (zero or more) can be either letters or digits.
Step 2: Requirements for the NFA.
The NFA must:
1. Start with a transition on a letter.
2. Allow looping transitions (possibly via \(\epsilon\) moves) for both letter and digit.
3. Have at least one accepting state that can be reached after consuming the input.
Step 3: Analysis of options.
- Option (A): Does not correctly capture looping behavior for arbitrary sequences of letters and digits.
- Option (B): Splits states but does not enforce the correct structure for \((letter|digit)^*\).
- Option (C): Correctly models:
\hspace{0.5cm• Initial state requires a letter.
\hspace{0.5cm• Then via \(\epsilon\) transitions, moves into loops that accept letter or digit.
\hspace{0.5cm• Accepting state reached correctly after any sequence.
- Option (D): Incomplete — does not ensure repetition of letter or digit in the correct manner.
Step 4: Conclusion.
Only Option (C) satisfies the definition of identifiers.
\[ \boxed{The correct NFA is (C).} \] Quick Tip: Identifiers in most programming languages must start with a letter, followed by letters or digits. This is why the automaton must force a letter} first, and only then allow repetition of both letters and digits.
An algorithm has to store several keys generated by an adversary in a hash table. The adversary is malicious who tries to maximize the number of collisions. Let \(k\) be the number of keys, \(m\) be the number of slots in the hash table, and \(k > m\). Which one of the following is the best hashing strategy to counteract the adversary?
View Solution
Step 1: Recall the problem.
The adversary is generating keys maliciously, with the intention of maximizing collisions in the hash table. Thus, a deterministic hash function (like division or multiplication method) can be exploited by the adversary.
Step 2: Why division and multiplication fail.
- \emph{Division method: \(h(k) = k \bmod m\) is predictable. An adversary can easily choose keys that collide modulo \(m\).
- \emph{Multiplication method: Though better, it is still deterministic and predictable if the adversary knows the constant \(A\).
Step 3: Advantage of universal hashing.
Universal hashing selects a hash function randomly from a family of hash functions. Since the adversary cannot predict which function will be used, they cannot deliberately choose colliding keys. This minimizes the expected number of collisions.
Step 4: Conclusion.
Universal hashing is the best strategy against an adversary trying to maximize collisions, because it introduces randomness and unpredictability in hash function selection.
\[ \boxed{Universal hashing method is the best choice.} \] Quick Tip: When facing adversarial key generation in hashing, use \emph{universal hashing}. Randomization ensures that the adversary cannot predict collisions, unlike deterministic methods.
The output of a 2-input multiplexer is connected back to one of its inputs as shown in the figure. Match the functional equivalence of this circuit to one of the following options.
View Solution
Step 1: Understanding the circuit.
A 2-to-1 multiplexer has two data inputs (labelled 0 and 1), one select input (S), and one output (Q).
Here, the output \(Q\) is fed back to input '0', while an external data input is applied at input '1'.
Step 2: Behavior of the MUX.
When \(S=0\): The multiplexer output \(Q\) is connected to input '0'. But since '0' is already \(Q\), this creates a feedback loop and the output holds its previous value.
When \(S=1\): The multiplexer output \(Q\) follows the external data input (D).
Step 3: Functional equivalence.
This is exactly how a D latch works:
When Enable (S=1) \(\Rightarrow\) Output follows input D.
When Enable (S=0) \(\Rightarrow\) Output holds its previous value.
Step 4: Eliminating wrong options.
(A) D Flip-flop: Requires clock edge triggering, which is not present here. So False.
(C) Half-adder: Performs arithmetic sum of two bits, not related here. False.
(D) Demultiplexer: Performs data distribution to multiple outputs, not applicable here. False.
\[ \boxed{The circuit is functionally equivalent to a D Latch.} \] Quick Tip: A multiplexer with feedback can easily implement latches.
Remember: MUX + feedback \(\Rightarrow\) Latch.
Latches are level-sensitive, while flip-flops are edge-triggered.
Which one or more of the following need to be saved on a context switch from one thread (T1) of a process to another thread (T2) of the same process?
View Solution
Step 1: Understanding context switch
When switching from one thread (T1) to another (T2) within the \emph{same process, the CPU must save the current execution state of T1 and load the execution state of T2.
This execution state primarily consists of CPU registers and pointers required to resume execution later.
Step 2: Evaluating each option
- (A) Page table base register:
All threads of the same process share the same virtual address space, hence the same page table base register.
Therefore, it does not need to be saved or changed during a thread-to-thread context switch.
\(\Rightarrow\) Not required.
- (B) Stack pointer:
Each thread maintains its own stack (for function calls, local variables, return addresses).
To resume T2 correctly, its stack pointer must be restored.
\(\Rightarrow\) Must be saved/restored.
- (C) Program counter:
The program counter (PC) holds the address of the next instruction to execute.
Without saving/restoring the PC, the thread cannot resume from where it left off.
\(\Rightarrow\) Must be saved/restored.
- (D) General purpose registers:
General purpose registers (like AX, BX in x86, or r0, r1 in ARM) hold intermediate data during computation.
Each thread requires its own register values to resume correctly.
\(\Rightarrow\) Must be saved/restored.
Step 3: Conclusion
Only the thread-specific state (stack pointer, program counter, and general registers) needs to be saved/restored.
The address-space-related state (page table base register) remains unchanged because threads of a process share memory.
\[ \boxed{Correct Statements: (B), (C), and (D)} \] Quick Tip: In thread context switching, save only the thread-specific CPU state (SP, PC, registers).
In process context switching, save both CPU state and memory-related state (page tables, segment tables).
Which one or more of the following options guarantee that a computer system will transition from user mode to kernel mode?
View Solution
Step 1: Analyze Option (A) Function Call
A normal function call in user space executes entirely in user mode. It does not involve the operating system kernel. Hence, there is no user-to-kernel mode switch.
\(\Rightarrow\) (A) is False.
Step 2: Analyze Option (B) malloc Call
The \texttt{malloc() function is part of the C standard library. In most cases, it only allocates memory from the heap of the process without involving the kernel.
However, if more memory is required, it may internally invoke a system call such as \texttt{brk() or \texttt{mmap(), which would cause a kernel transition. But this is not guaranteed for every malloc call.
\(\Rightarrow\) (B) is False.
Step 3: Analyze Option (C) Page Fault
A page fault occurs when a program accesses a memory page that is not present in physical memory. This is a hardware exception, which always triggers the operating system’s page fault handler in the kernel.
Thus, the CPU must switch to kernel mode to handle it.
\(\Rightarrow\) (C) is True.
Step 4: Analyze Option (D) System Call
System calls are explicit requests made by a user process to the operating system for services like I/O, process management, or memory management.
Executing a system call instruction (e.g., \texttt{int 0x80, \texttt{syscall) always causes a trap into kernel mode.
\(\Rightarrow\) (D) is True.
\[ \boxed{Correct Options: (C) Page Fault and (D) System Call} \] Quick Tip: User-level function calls and library calls (like malloc) usually remain in user mode. Kernel entry is guaranteed only by hardware exceptions (like page faults) or explicit system calls.
Which of the following statements is/are CORRECT?
View Solution
Step 1: Regular languages under intersection (A)
Regular languages are closed under all Boolean operations. Given DFAs \(M_1\) for \(L_1\) and \(M_2\) for \(L_2\), construct the \emph{product automaton \(M\) whose state set is \(Q_1 \times Q_2\), start state \((q_{1,0}, q_{2,0})\), transition \(\delta\big((p,q),a\big)=(\delta_1(p,a),\delta_2(q,a))\), and accepting set \(F_1 \times F_2\). Then \(L(M)=L_1 \cap L_2\).
\Rightarrow\; (A) True.
Step 2: Context-free languages under intersection (B)
CFLs are \emph{not closed under intersection in general (they are closed under intersection with regular languages, but not with arbitrary CFLs). A standard counterexample is:
\[ L_1=\{\,a^i b^i c^k \mid i,k \ge 0\,\},\qquad L_2=\{\,a^k b^i c^i \mid i,k \ge 0\,\}, \]
both of which are context-free. Their intersection is
\[ L_1 \cap L_2=\{\,a^n b^n c^n \mid n \ge 0\,\}, \]
which is a classic \emph{non-CFL.
\Rightarrow\; (B) False.
Step 3: Recursive (decidable) languages under intersection (C)
If \(L_1\) and \(L_2\) are recursive (decidable), there exist Turing machines \(D_1,D_2\) that \emph{halt on all inputs and decide membership for \(L_1,L_2\) respectively. Build a decider \(D\) for \(L_1 \cap L_2\) that runs \(D_1\) and \(D_2\) sequentially (or in parallel) and accepts iff both accept; otherwise rejects. Since both \(D_1\) and \(D_2\) halt on every input, \(D\) also halts on every input.
\Rightarrow\; (C) True.
Step 4: Recursively enumerable languages under intersection (D)
If \(L_1\) and \(L_2\) are recursively enumerable (RE), there exist \emph{recognizers \(R_1,R_2\) that accept exactly the strings in \(L_1,L_2\) (they may loop forever on strings not in the language). To recognize \(L_1 \cap L_2\), dovetail: simulate one step of \(R_1\), then one step of \(R_2\), and so on; accept the input iff \emph{both \(R_1\) and \(R_2\) eventually accept. If the input is not in the intersection, at least one recognizer will never accept, so our machine never accepts—exactly the RE behavior.
\Rightarrow\; (D) True.
\[ \boxed{Correct statements: (A), (C), and (D).} \] Quick Tip: Remember the closure table: Regular \(\Rightarrow\) closed under \(\cap\); CFLs are not closed under \(\cap\) (but are closed under \(\cap\) with Regular); Recursive (decidable) sets are closed under all Boolean operations; RE sets are closed under \(\cup\) and \(\cap\) (via dovetailing recognizers) but not under complement.
Which of the following statements is/are INCORRECT about the OSPF (Open Shortest Path First) routing protocol used in the Internet?
View Solution
Statement (A): Incorrect.
OSPF does not use the Bellman-Ford algorithm. Bellman-Ford is used by distance vector protocols like RIP (Routing Information Protocol). OSPF is a link-state protocol and uses Dijkstra’s algorithm. Hence, this statement is False.
Statement (B): Correct.
OSPF is based on link-state routing and indeed uses Dijkstra’s shortest path algorithm to calculate least-cost paths from source to all other nodes in the network. Hence, this statement is True.
Statement (C): Incorrect.
OSPF is an intra-domain (or interior gateway) protocol, used within an Autonomous System (AS). Inter-domain routing protocols are BGP (Border Gateway Protocol). Hence, calling OSPF inter-domain is False.
Statement (D): Correct.
OSPF allows hierarchical routing by dividing the network into multiple areas. This reduces routing overhead and improves scalability. Hence, this statement is True.
\[ \boxed{Incorrect Statements: (A) and (C)} \] Quick Tip: Remember: OSPF is a link-state routing protocol using Dijkstra’s algorithm and works as an intra-domain protocol. Bellman-Ford is for RIP, while BGP is used for inter-domain routing.
Geetha has a conjecture about integers, of the form \(\forall x\big(P(x)\Rightarrow \exists y\,Q(x,y)\big)\), where \(P\) is a statement about integers and \(Q\) is a statement about pairs of integers. Which of the following option(s) would \emph{imply Geetha's conjecture?
View Solution
Target statement (Geetha's conjecture): \(\forall x\big(P(x)\Rightarrow \exists y\,Q(x,y)\big)\).
This reads: for every \(x\), if \(P(x)\) holds, then there exists (possibly \(x\)-dependent) \(y\) such that \(Q(x,y)\) holds.
Check (A): \(\exists x\big(P(x)\wedge \forall y\,Q(x,y)\big)\).
This asserts that there is \emph{some single \(x_0\) for which \(P(x_0)\) holds and \(Q(x_0,y)\) holds for \emph{all \(y\).
It provides no information about other values of \(x\) where \(P(x)\) might be true.
Therefore (A) does \emph{not imply the target \(\forall x\big(P(x)\Rightarrow \exists y\,Q(x,y)\big)\). \(\Rightarrow\) False.
Check (B): \(\forall x\,\forall y\,Q(x,y)\).
If \(Q(x,y)\) is true for all \(x\) and all \(y\), then in particular for any \(x\) with \(P(x)\) true, we can choose \emph{any \(y\) and \(Q(x,y)\) will hold.
Hence \(\forall x\big(P(x)\Rightarrow \exists y\,Q(x,y)\big)\) follows immediately. \(\Rightarrow\) True.
Check (C): \(\exists y\,\forall x\big(P(x)\Rightarrow Q(x,y)\big)\).
This says there exists a \emph{single fixed \(y_0\) such that for all \(x\), if \(P(x)\) then \(Q(x,y_0)\).
Then for each \(x\) with \(P(x)\), we can witness the existential in the target by choosing that same \(y_0\).
Thus \(\forall x\big(P(x)\Rightarrow \exists y\,Q(x,y)\big)\) holds. \(\Rightarrow\) True.
Check (D): \(\exists x\big(P(x)\wedge \exists y\,Q(x,y)\big)\).
This only guarantees one particular \(x_0\) with \(P(x_0)\) and some \(y_0\) s.t.\ \(Q(x_0,y_0)\).
It gives no guarantee for other \(x\) where \(P(x)\) might hold.
Therefore (D) does \emph{not imply the target universal conditional. \(\Rightarrow\) False.
\[ \boxed{Options that imply Geetha's conjecture: (B) and (C).} \] Quick Tip: To test whether a stronger statement implies \(\forall x\,(P(x)\Rightarrow \exists y\,Q(x,y))\), ask: for each \(x\) with \(P(x)\), can I point to at least one \(y\) (possibly depending on \(x\)) making \(Q(x,y)\) true?
Statements that provide a \emph{global} witness \(y\) for all such \(x\) (as in (C)) or make \(Q\) true for all \(x,y\) (as in (B)) will imply the target; statements about only \emph{some} \(x\) do not.
Which one or more of the following CPU scheduling algorithms can potentially cause starvation?
View Solution
Step 1: Analyze Option (A) First-in First-Out (FIFO)
In FIFO (or FCFS), processes are scheduled in the order of their arrival. However, a very long job at the front can delay all other processes (known as the “convoy effect”). Short processes behind it may wait indefinitely long if long jobs keep arriving. This is a form of starvation.
\(\Rightarrow\) (A) can cause starvation.
Step 2: Analyze Option (B) Round Robin
Round Robin ensures fairness by giving each process a fixed time slice in cyclic order. Every process eventually gets CPU time, so starvation is avoided.
\(\Rightarrow\) (B) does not cause starvation.
Step 3: Analyze Option (C) Priority Scheduling
In Priority Scheduling, higher priority processes are executed first. If higher-priority processes keep arriving, lower-priority processes may never get CPU time. This indefinite waiting is starvation.
\(\Rightarrow\) (C) can cause starvation.
Step 4: Analyze Option (D) Shortest Job First (SJF)
In non-preemptive SJF, if short jobs keep arriving, longer jobs may get postponed indefinitely. In preemptive SJF (Shortest Remaining Time First), a long process can be repeatedly preempted by shorter ones. Both situations may lead to starvation of long processes.
\(\Rightarrow\) (D) can cause starvation.
\[ \boxed{Correct Options: (A) FIFO, (C) Priority Scheduling, and (D) Shortest Job First} \] Quick Tip: Starvation happens when some processes wait indefinitely. It commonly occurs in scheduling policies that favor certain types of jobs (short jobs or high-priority jobs). Round Robin avoids starvation since every process gets CPU time fairly.
Let \[ f(x) = x^3 + 15x^2 - 33x - 36 \]
be a real-valued function. Which of the following statements is/are TRUE?
View Solution
Step 1: Find critical points.
We first compute the derivative of \(f(x)\): \[ f'(x) = \frac{d}{dx}(x^3 + 15x^2 - 33x - 36) = 3x^2 + 30x - 33. \]
Factorize: \[ f'(x) = 3(x^2 + 10x - 11) = 3(x+11)(x-1). \]
So, critical points are at \[ x = -11 and x = 1. \]
Step 2: Use the second derivative test.
Compute \(f''(x)\): \[ f''(x) = \frac{d}{dx}(3x^2 + 30x - 33) = 6x + 30. \]
At \(x = -11\): \[ f''(-11) = 6(-11) + 30 = -66 + 30 = -36 < 0, \]
which indicates a local maximum.
At \(x = 1\): \[ f''(1) = 6(1) + 30 = 36 > 0, \]
which indicates a local minimum.
Step 3: Verify statements.
- (A) False, because \(f(x)\) \emph{does have a local maximum at \(x = -11\).
- (B) True, \(f(x)\) has a local maximum at \(x = -11\).
- (C) False, because \(f(x)\) \emph{does have a local minimum at \(x = 1\).
- (D) True, \(f(x)\) has a local minimum at \(x = 1\).
\[ \boxed{Correct statements: (B) and (D).} \] Quick Tip: For cubic polynomials, critical points are obtained from the quadratic derivative \(f'(x)\). Use \(f''(x)\) to classify them: negative \(\Rightarrow\) maximum, positive \(\Rightarrow\) minimum. A cubic can have both a local max and a local min.
Let \(f\) and \(g\) be functions of natural numbers given by \(f(n)=n\) and \(g(n)=n^2\). Which of the following statements is/are TRUE?
View Solution
We are given: \(f(n) = n\), \(g(n) = n^2\).
Step 1: Check \(f \in O(g)\).
We ask if \(f(n) \leq c \cdot g(n)\) for some constant \(c > 0\) and sufficiently large \(n\).
That is, \(n \leq c \cdot n^2\).
For \(n \geq 1/c\), this inequality holds true.
Hence, \(f \in O(g)\) is True.
Step 2: Check \(f \in \Omega(g)\).
We ask if \(f(n) \geq c \cdot g(n)\) for some \(c > 0\) and sufficiently large \(n\).
That is, \(n \geq c \cdot n^2 \Rightarrow 1 \geq c \cdot n\).
This cannot hold for large \(n\).
Hence, \(f \in \Omega(g)\) is False.
Step 3: Check \(f \in o(g)\).
We check the limit: \(\lim_{n \to \infty} \frac{f(n)}{g(n)} = \lim_{n \to \infty} \frac{n}{n^2} = \lim_{n \to \infty} \frac{1}{n} = 0\).
Since the limit is \(0\), \(f \in o(g)\) is True.
Step 4: Check \(f \in \Theta(g)\).
For \(\Theta\), \(f(n)\) must be both \(O(g)\) and \(\Omega(g)\).
We have \(f \in O(g)\) but not in \(\Omega(g)\).
Hence, \(f \notin \Theta(g)\). False.
\[ \boxed{True Statements: (A) and (C)} \] Quick Tip: Remember: If \(f(n)\) grows slower than \(g(n)\), then \(f \in O(g)\) and also \(f \in o(g)\), but not \(\Omega(g)\) or \(\Theta(g)\).
Let \(A\) be the adjacency matrix of the given graph with vertices \(\{1,2,3,4,5\}\). Let \(\lambda_1,\lambda_2,\lambda_3,\lambda_4,\lambda_5\) be the eigenvalues of \(A\) (not necessarily distinct). Find \(\lambda_1+\lambda_2+\lambda_3+\lambda_4+\lambda_5 = \; \).
View Solution
Step 1 (Key fact): For any square matrix \(A\), the sum of its eigenvalues equals \(\mathrm{tr}(A)\), the trace of \(A\). Hence \(\sum_{i=1}^{5}\lambda_i=\mathrm{tr}(A)=\sum_{i=1}^{5}A_{ii}\).
Step 2 (Adjacency diagonal entries): In the standard adjacency-matrix convention used in such problems, each self-loop at a vertex contributes \(2\) on the diagonal (so that the row sum equals the degree counting a loop twice).
Step 3 (Read the graph): The picture shows self-loops at vertices \(3\) and \(4\), and no loops at \(1,2,5\). Therefore, \(A_{33}=2,\; A_{44}=2,\; A_{11}=A_{22}=A_{55}=0\).
Step 4 (Trace and sum of eigenvalues): \(\mathrm{tr}(A)=A_{11}+A_{22}+A_{33}+A_{44}+A_{55}=0+0+2+2+0=4\).
\(\Rightarrow\) \(\lambda_1+\lambda_2+\lambda_3+\lambda_4+\lambda_5=4\).
\[ \boxed{4} \] Quick Tip: For adjacency matrices, \(\sum \lambda_i=\mathrm{tr}(A)\). If loops are present, many graph-theory conventions count each loop as \(2\) on the diagonal so that row sums equal vertex degrees. Always check the loop convention—here it yields \(A_{33}=A_{44}=2\).
The value of the definite integral \(\displaystyle \int_{-3}^{3}\int_{-2}^{2}\int_{-1}^{1}\big(4x^{2}y - z^{3}\big)\,dz\,dy\,dx\) is __________. (Rounded off to the nearest integer)
View Solution
Step 1: Integrate w.r.t. \(z\)
\(\displaystyle \int_{-1}^{1} \big(4x^{2}y - z^{3}\big)\,dz = \left[4x^{2}y\,z - \frac{z^{4}}{4}\right]_{-1}^{1} = 4x^{2}y(1-(-1)) - \frac{1-1}{4} = 8x^{2}y.\)
\(\Rightarrow\) The triple integral reduces to \(\displaystyle \int_{-3}^{3}\int_{-2}^{2} 8x^{2}y\,dy\,dx.\)
Step 2: Integrate w.r.t. \(y\)
\(\displaystyle \int_{-2}^{2} 8x^{2}y\,dy = 8x^{2}\left[\frac{y^{2}}{2}\right]_{-2}^{2} = 4x^{2}\,(4-4)=0.\)
\(\Rightarrow\) The inner two integrals already give \(0\), so the outer \(x\)-integral is also \(0\).
(Equivalent symmetry argument)
\(4x^{2}y\) is \emph{odd in \(y\) over \([-2,2]\Rightarrow\) integrates to \(0\). \(-z^{3}\) is \emph{odd in \(z\) over \([-1,1]\Rightarrow\) integrates to \(0\).
Hence the whole triple integral is \(0\).
\[ \boxed{0} \] Quick Tip: Before grinding through multivariable integrals, check for odd/even symmetry over symmetric limits. Odd parts vanish immediately, saving time.
A particular number is written as \(132\) in radix-\(4\) representation. The same number in radix-\(5\) representation is \(\_\_\_\_\_\_\_\_\).
View Solution
Step 1: Convert \(132_{4}\) to decimal.
\[ 132_{4} = 1 \cdot 4^2 + 3 \cdot 4^1 + 2 \cdot 4^0 \] \[ = 1 \cdot 16 + 3 \cdot 4 + 2 \cdot 1 \] \[ = 16 + 12 + 2 = 30_{10}. \]
Step 2: Convert decimal \(30_{10}\) to base-5.
Divide by 5 repeatedly: \[ 30 \div 5 = 6 remainder 0 \] \[ 6 \div 5 = 1 remainder 1 \] \[ 1 \div 5 = 0 remainder 1 \]
Reading remainders from bottom to top: \[ 30_{10} = 110_{5}. \]
\[ \boxed{132_{4} = 110_{5}} \] Quick Tip: To convert between different bases, always first go through base 10 (decimal) unless a direct pattern is obvious. Divide by the target base and collect remainders bottom-up.
Consider a 3-stage pipelined processor having a delay of 10 ns, 20 ns, and 14 ns for the first, second, and third stages, respectively. Assume that there is no other delay and the processor does not suffer from any pipeline hazards. Also assume that one instruction is fetched every cycle.
The total execution time for executing 100 instructions on this processor is _________ ns.
View Solution
Step 1: Determine pipeline clock period.
The cycle time of a synchronous pipeline is set by the slowest stage.
Given stage delays: \(10\) ns, \(20\) ns, \(14\) ns \(\Rightarrow\) clock period \(T_c=\max(10,20,14)=20\) ns.
Step 2: Compute total time for \(N\) instructions in a \(k\)-stage pipeline.
Total time \(T = (k + N - 1)\,T_c\), where \(k=3\) stages and \(N=100\) instructions.
So, \(T=(3+100-1)\times 20=(102)\times 20=2040\) ns.
\[ \boxed{T=2040~ns} \] Quick Tip: For an ideal \(k\)-stage pipeline with no hazards and negligible latch overhead: \(T=(k+N-1)\times \max\{stage delays\}\). The first instruction takes \(kT_c\); each subsequent one completes every \(T_c\).
A keyboard connected to a computer is used at a rate of 1 keystroke per second. The computer polls the keyboard every 10 ms, each poll takes 100 \(\mu s\). If a key is detected, an additional 200 \(\mu s\) is used for processing. Let \(T_1\) be the fraction of a second spent in polling and processing a keystroke. In an alternative implementation with interrupts, each keystroke requires 1 ms to service and process. Let \(T_2\) be the fraction of a second in the interrupt method. Find the ratio \(T_1/T_2\).
View Solution
Step 1: Polling implementation (T1)
- Polling frequency = once every \(10\,ms\).
- In 1 second = \(\tfrac{1}{0.01} = 100\) polls.
- Each poll consumes \(100 \mu s = 0.0001 \,s\).
- Total polling overhead in 1 second = \(100 \times 0.0001 = 0.01 \,s\).
- Additionally, when a key is pressed (once per second), extra \(200 \mu s = 0.0002 \,s\) is used.
- Total time spent = \(0.01 + 0.0002 = 0.0102 \,s\).
- Thus, \(T_1 = 0.0102\).
Step 2: Interrupt implementation (T2)
- For each keystroke, interrupt servicing + processing = \(1 \,ms = 0.001 \,s\).
- Since keystroke rate = 1 per second, total fraction per second = \(0.001\).
- Thus, \(T_2 = 0.001\).
Step 3: Ratio
\[ \frac{T_1}{T_2} = \frac{0.0102}{0.001} = 10.2 \]
\[ \boxed{10.2} \] Quick Tip: Polling wastes CPU time because it repeatedly checks the device even when idle, while interrupts only use CPU when actual input arrives. This is why interrupt-driven I/O is far more efficient in practice.
The integer value printed by the ANSI-C program given below is _________.
#include
int funcp(){
static int x = 1;
x++;
return x;
int main(){
int x,y;
x = funcp();
y = funcp() + x;
printf("%d\n", (x+y));
return 0;
View Solution
Step 1: Understanding \texttt{static int x} in funcp()
The variable \texttt{x inside \texttt{funcp() is declared as \texttt{static, so it retains its value across multiple function calls. Initially, \texttt{x = 1.
Step 2: First function call (in \texttt{x = funcp();})
- On entry, \texttt{x = 1.
- Increment: \texttt{x++ makes it \texttt{2.
- Function returns \texttt{2.
So now in \texttt{main(), \texttt{x = 2.
Step 3: Second function call (in \texttt{y = funcp() + x;})
- On entry, the static variable \texttt{x inside \texttt{funcp() is now \texttt{2 (retained from last call).
- Increment: \texttt{x++ makes it \texttt{3.
- Function returns \texttt{3.
Thus, \texttt{y = 3 + x(main) = \(3 + 2 = 5\).
Step 4: Final output (printf)
The program prints \((x + y) = (2 + 5) = 7\).
\[ \boxed{7} \] Quick Tip: Remember that \texttt{static} variables inside a function preserve their value between successive calls. This is often tested in C programming exam questions.
Consider the following program:
int main() {
f1();
f2(2);
f3();
return(0);
int f1() {
f1();
return(1);
int f2(int X) {
f3();
if (X==1)
return f1();
else
return (X * f2(X-1));
int f3() {
return(5);
Which one of the following options represents the activation tree corresponding to the main function?
View Solution
Step 1: Understand function calls in \texttt{main()}.
The function \texttt{main() calls: \[ f1(); f2(2); f3(); \]
So, the activation tree root (\texttt{main) has three children: \(f1\), \(f2\), and \(f3\).
Step 2: Analyze \texttt{f1()}.
\texttt{f1() calls itself recursively once and then returns 1.
So \(f1\) has a recursive self-call in the activation tree.
Step 3: Analyze \texttt{f2(2)}.
For \(f2(2)\):
- It first calls \(f3()\).
- Since \(X=2 \neq 1\), it returns \(2 * f2(1)\).
- Now \(f2(1)\) calls \(f3()\) and then returns \(f1()\).
So inside \(f2(2)\), we have calls: \(f3 \to f2(1) \to (f3, f1)\).
Step 4: Analyze \texttt{f3()}.
\texttt{f3() simply returns 5 with no further calls.
Step 5: Activation Tree Construction.
- Root: \texttt{main
- Child 1: \(f1\) (recursive call inside)
- Child 2: \(f2(2)\)
- \(f3\)
- \(f2(1)\)
- \(f3\)
- \(f1\)
- Child 3: \(f3\)
This exactly matches option (A).
\[ \boxed{Correct Option: (A)} \] Quick Tip: When drawing activation trees, always expand function calls step by step, including recursive calls. Each call becomes a node, and its direct calls become its children.
Consider the control flow graph shown. Which one of the following choices correctly lists the set of live variables at the exit point of each basic block?
View Solution
Step 1: Recall live variable analysis.
A variable is live at a program point if its value will be used on some path in the future before being redefined.
Step 2: Analyze block B4.
B4 computes \(i = a + 1\). Hence, \(a\) must be live at the entry of B4.
After B4, control flows back to B2, so both \(i\) and \(j\) may be needed again.
Thus, live set at exit of B4: \{a, i, j\.
Step 3: Analyze block B3.
B3 assigns \(a = 20\) and flows into B4. In B4, \(a\) is used. Hence, \(a\) must be live at B3’s exit.
Also, since B4 requires \(j\) through the loop, \(j\) is live too.
Thus, exit(B3) = \{a, j\.
Step 4: Analyze block B2.
B2 assigns \(i = i + 1\) and \(j = j - 1\). Its successors are B3 and B4.
- From B3: exit(B3) = \{a, j\.
- From B4: exit(B4) = \{a, i, j\.
So, overall live variables at exit(B2) = \{a, j\. (Because \(i\) defined in B2 is redefined before use).
Step 5: Analyze block B1.
B1 initializes \(i = m-1, j = n, a = 10\). Its successor is B2, where live set is \{a, j\. Also, eventually \(i\) is required later in the loop.
Thus, exit(B1) = \{a, i, j\.
\[ \boxed{B1: \{a, i, j\, B2: \{a, j\, B3: \{a, j\}, B4: \{a, i, j\}}} \] Quick Tip: Live variable analysis flows backward}: start from the use points and propagate towards the entry. A variable is live if it is used along some path before being redefined.
Consider the two functions \texttt{incr} and \texttt{decr} below. Five threads each call \texttt{incr} once and three threads each call \texttt{decr} once on the same shared variable \(X\) (initially \(10\)). There are two semaphore implementations:
I-1: \(s\) is a binary semaphore initialized to \(1\). I-2: \(s\) is a counting semaphore initialized to \(2\).
Let \(V_1, V_2\) be the values of \(X\) at the end of all threads for I-1 and I-2, respectively. Which choice gives the \emph{minimum possible values of \(V_1, V_2\)?
incr(){ decr(){
wait(s); wait(s);
X = X + 1; X = X - 1;
signal(s); signal(s);
View Solution
Step 1: I-1 (binary semaphore \(s=1\))
Binary semaphore enforces mutual exclusion; each update to \(X\) is atomic.
Net effect \(=\) \(5\) increments and \(3\) decrements \(= +2\).
So the final value is \(V_1 = 10 + 2 = 12\).
Step 2: I-2 (counting semaphore \(s=2\)) — race possible
At most two threads may be in the critical section simultaneously. Lost-update patterns can occur:
\(\bullet\) inc\(+\)inc overlap: both read the same \(v\), both write \(v+1\) \(\Rightarrow\) net \(+1\) instead of \(+2\) (lose one increment).
\(\bullet\) inc\(+\)dec overlap (dec last): both read the same \(v\); if the decrement writes last, final is \(v-1\) \(\Rightarrow\) net \(-1\) instead of \(0\).
\(\bullet\) dec\(+\)dec overlap: both read \(v\), both write \(v-1\) \(\Rightarrow\) net \(-1\) instead of \(-2\) (this \emph{hurts minimization, so we avoid it).
To minimize \(X\): pair each of the \(3\) decrements with an increment (schedule decrement’s write last) to get three \(-1\) effects. That uses \(3\) increments and \(3\) decrements.
The remaining \(2\) increments can overlap with each other to yield only \(+1\) (rather than \(+2\)).
Hence the minimum total change is \(-1-1-1 + 1 = -2\).
Therefore \(V_2 = 10 - 2 = 8\).
\[ \boxed{(V_1,V_2) = (12,8)} \] Quick Tip: With a counting semaphore \(=2\), at most two threads race at once. The best way to minimize the final value is to let each decrement overwrite a concurrent increment (making a pair worth \(-1\)), and make the leftover increments collide with each other (worth \(+1\)). You cannot reduce all five increments because only three decrements exist and at most two threads can overlap at any instant.
Consider the context-free grammar \(G\) below:
\[ S \;\to\; aSb \;|\; X \] \[ X \;\to\; aX \;|\; Xb \;|\; a \;|\; b \]
where \(S\) and \(X\) are non-terminals, and \(a\) and \(b\) are terminal symbols. The starting non-terminal is \(S\).
Which one of the following statements is CORRECT?
View Solution
Step 1: Analyze production \(S \to aSb \;|\; X\)
This rule allows wrapping equal numbers of \(a\)'s at the left and \(b\)'s at the right around whatever is produced by \(X\). Hence, any string generated by \(S\) has the form: \[ a^n \; w \; b^n where w \in L(X),\; n \geq 0 \]
Step 2: Analyze production of \(X\)
The productions of \(X\) are: \[ X \to aX \;|\; Xb \;|\; a \;|\; b \]
This means \(X\) can produce:
- Start with a base case: \(a\) or \(b\).
- Then prepend any number of \(a\)'s or append any number of \(b\)'s.
Thus, \(X\) generates all strings of the form: \[ X = a^i \; \alpha \; b^j where \alpha \in \{a, b\}, \; i,j \geq 0 \]
In other words, \(X\) produces a string with some leading \(a\)'s, then a single terminal \(a\) or \(b\), followed by some trailing \(b\)'s.
Step 3: Combine with \(S\)
Since \(S \to a^n \; w \; b^n\), with \(w \in L(X)\), the final language is: \[ L(G) = \{\, a^n \; (a^i \alpha b^j) \; b^n \mid n,i,j \geq 0,\; \alpha \in \{a,b\}\,\} \]
This simplifies to: \[ L(G) = a^*(a+b)b^* \]
because the total left \(a\)'s combine, and the total right \(b\)'s combine.
Step 4: Conclusion
The language generated is regular and corresponds exactly to option (B): \[ L(G) = a^*(a+b)b^* \]
\[ \boxed{Correct Option: (B)} \] Quick Tip: When analyzing CFGs, first identify the “core string” generated by one non-terminal, then check how other rules wrap or extend it. Here, \(X\) gives \(a^*(a+b)b^*\), and \(S\) just reinforces this same structure.
Consider the pushdown automaton (PDA) \(P\) over input alphabet \(\{a,b\}\) and stack alphabet \(\{\perp,A\}\) with start state \(s\) and acceptance by \emph{empty stack. The transition sketch shows: in \(s\) on each \(a\) it \emph{pushes one \(A\) (i.e., \(a/\perp \to A\perp\) and \(a/A \to AA\)); on first \(b\) it goes to \(p\) with \(b/A \to \epsilon\) and stays in \(p\) popping one \(A\) per \(b\) (\(b/A \to \epsilon\)); from \(p\) it may go to \(q\) by \(\epsilon/A \to \epsilon\) and in \(q\) it can keep popping \(A\)’s and finally pop \(\perp\) by \(\epsilon/\perp \to \epsilon\). Which option describes \(L(P)\)?
View Solution
Step 1: Effect of the \(a\)-loop at \(s\).
While reading \(a\)’s in state \(s\), the PDA pushes exactly one \(A\) per \(a\) (\(a/\perp \mapsto A\perp\) and \(a/A \mapsto AA\)).
Hence, after \(m\ge 1\) \(a\)’s, the stack is \(A^m\perp\).
Step 2: Switching to \(b\)’s and popping in \(p\).
On the first \(b\), the PDA must move \(s \to p\) with \(b/A \mapsto \epsilon\), and in \(p\) it keeps popping one \(A\) per \(b\) (\(b/A \mapsto \epsilon\)).
Thus after reading \(n\) \(b\)’s in \(p\), \(n\) \(A\)’s are popped, leaving \(A^{m-n}\perp\).
Step 3: Empty-stack acceptance via \(q\).
From \(p\) there is an \(\epsilon\)-move that \emph{requires an \(A\) on top: \(\epsilon/A \mapsto \epsilon\) to enter \(q\), and in \(q\) the PDA can pop the remaining \(A\)’s and finally pop \(\perp\) by \(\epsilon/\perp \mapsto \epsilon\), achieving empty stack.
Therefore the PDA can accept \emph{only if after consuming the input we still have at least one \(A\) left (so we can take the \(\epsilon/A\) move to \(q\)), i.e., when \(m-n \ge 1 \Rightarrow n < m\).
Step 4: Excluding the boundary cases.
If \(n=m\), then after all \(b\)’s the stack is just \(\perp\); there is \emph{no \(\epsilon/\perp\) transition from \(p\) to empty the stack, because the move to \(q\) needs an \(A\) on top. Hence \(n=m\) is rejected.
If \(n>m\), at some \(b\) the top is \(\perp\) and \(b/\perp\) is undefined, so the input is rejected.
Hence the language is exactly \[ L(P)=\{\,a^m b^n \mid 1 \le m and n
\[ \boxed{L(P)=\{a^m b^n \mid 1 \le m,\; n
Consider the given C-code and its corresponding assembly code, with a few
operands U1–U4 being unknown. Some useful information as well as the semantics
of each unique assembly instruction is annotated as inline comments in the code.
The memory is byte-addressable.
View Solution
C-code: \texttt{for(i=0;i<10;i++) a[i] = b[i] * 8;
Registers: \(r1 \leftarrow 0\), \(r2 \leftarrow 10\), \(r3 \leftarrow\) base of \(a\), \(r4 \leftarrow\) base of \(b\).
Step 1 (Multiply by 8 \(\Rightarrow\) shift left by 3).
L03: \texttt{shl r5, r5, U1 must implement \(r5 \gets r5 \ll U1\) so that \(b[i] \times 8\) is computed \(\Rightarrow U1=3\).
Step 2 (Address increments for 32-bit ints).
Each \texttt{int is \(4\) bytes in a byte-addressable memory.
After storing to \(a[i]\) and loading \(b[i]\), the addresses must advance to the next element: \(r3 \gets r3 + U2\), \(r4 \gets r4 + U3\).
Thus \(U2=4\) and \(U3=4\).
Step 3 (Loop back target).
After L07 increments \(i\) (\(r1\)), control must jump to the loop test.
The comparison is at L01: \texttt{jeq r1, r2, end.
Hence the unconditional jump target is \(U4=L01\).
\[ \boxed{(U1,\,U2,\,U3,\,U4)=(3,\,4,\,4,\,L01)} \] Quick Tip: Array index steps in byte-addressable memory depend on element size: for 32-bit \texttt{int}, add \(4\) each iteration. Multiplying by \(2^k\) is just a left shift by \(k\).
A 4 KB byte-addressable memory is built using four 1 KB memory blocks. IA4 and IA3 feed a decoder that drives the active-high CS of the four blocks; the remaining ten address lines (all except IA4, IA3) go to the Addr inputs of each block. For each block, let \(X_1,X_2,X_3,X_4\) be the input memory address (IA11–IA0), in decimal, of its starting location (Addr \(=0\)). Which option is correct?
View Solution
Step 1 (Address split): Each 1 KB block needs \(10\) address bits \(\Rightarrow\) these are provided by all IA lines \emph{except IA4 and IA3.
Thus, when a block is at its start (Addr \(=0\)), all those \(10\) lines are \(0\).
Step 2 (Chip select via decoder): IA4\,(=A1) and IA3\,(=A0) select the block through the decoder outputs \(Q_0,Q_1,Q_2,Q_3\).
With Addr bits \(=0\), the only nonzero contribution to the global address comes from IA4 and IA3.
Step 3 (Starting addresses): Interpret IA11…IA0 as a binary number with only IA4 and IA3 possibly \(1\).
- For \(X_1\) (selected by \(Q_0\)): IA4\,IA3 \(=00 \Rightarrow\) value \(0\).
- For \(X_2\) (selected by \(Q_1\)): IA4\,IA3 \(=01 \Rightarrow\) value \(2^3=8\).
- For \(X_3\) (selected by \(Q_2\)): IA4\,IA3 \(=10 \Rightarrow\) value \(2^4=16\).
- For \(X_4\) (selected by \(Q_3\)): IA4\,IA3 \(=11 \Rightarrow\) value \(2^4+2^3=24\).
\[ \boxed{(X_1,X_2,X_3,X_4)=(0,8,16,24)} \] Quick Tip: When a subset of address lines drives the decoder for chip-select, the block base addresses differ only in those lines. With Addr \(=0\) inside each block, set the decoder-input bits to the block’s select code and zero all other address bits to read the global base address.
Consider a sequential digital circuit consisting of T flip-flops and D flip-flops as shown. At the beginning, \(Q_1=0\), \(Q_2=1\), \(Q_3=1\). Which one of the given values of \((Q_1,Q_2,Q_3)\) can \emph{NEVER be obtained with this circuit?
View Solution
Step 1: Write next–state equations
For a T–FF: \(Q^+ = Q \oplus T\). For a D–FF: \(Q^+ = D\).
From the figure (using the labels in the question): \[ \begin{aligned} T_1 &= \overline{Q_3}, & Q_1^+ &= Q_1 \oplus \overline{Q_3},
D_2 &= Q_1, & Q_2^+ &= Q_1,
T_3 &= Q_2, & Q_3^+ &= Q_3 \oplus Q_2. \end{aligned} \]
Step 2: Iterate from the given initial state \((Q_1,Q_2,Q_3)=(0,1,1)\)
On each rising edge (all FFs clocked together) apply the above equations:
\[ \begin{array}{c|c} Clock & (Q_1,Q_2,Q_3)
\hline 0 & (0,1,1)\ (given)
1 & (0,0,0)
2 & (1,0,0)
3 & (0,1,0)
4 & (1,0,1)
5 & (1,1,1)
6 & (1,1,0)
7 & (0,1,1)\ (cycle repeats) \end{array} \]
Step 3: Read off the reachable set
The reachable states are \(\{(0,1,1), (0,0,0), (1,0,0), (0,1,0), (1,0,1), (1,1,1), (1,1,0)\}\).
The tuple \((0,0,1)\) never appears and the sequence repeats thereafter, so it is \emph{unreachable.
\[ \boxed{State (0,0,1) can never be obtained.} \] Quick Tip: Translate the diagram into next–state equations first. Then either use algebraic constraints or a short state walk from the initial condition to spot unreachable tuples quickly.
A Boolean digital circuit is composed using two 4-input multiplexers (M1 and M2) and one 2-input multiplexer (M3) as shown in the figure. X0–X7 are the inputs of M1 and M2 and can be set to 0 or 1. The select lines of M1 and M2 are \((A,C)\), and the select line of M3 is \(B\). The output of M3 is the final circuit output.
Which one of the following sets of values of \((X0,X1,X2,X3,X4,X5,X6,X7)\) will realise the Boolean function \[ F(A,B,C) = \overline{A} + \overline{A}C + ABC \; ? \]
View Solution
Step 1: Understanding M1 and M2.
- M1 is a 4:1 MUX with select inputs \((A,C)\). Its inputs are \(X0,X1,X2,X3\). Hence M1 implements a function of \(A\) and \(C\).
- M2 is another 4:1 MUX with select inputs \((A,C)\), inputs \(X4,X5,X6,X7\). Hence M2 also implements a function of \(A\) and \(C\).
Step 2: Understanding M3.
- M3 is a 2:1 MUX with select line \(B\). Input 0 of M3 is the output of M1, and input 1 of M3 is the output of M2.
Thus, \[ F(A,B,C) = \overline{B} \cdot M1(A,C) + B \cdot M2(A,C). \]
Step 3: Desired function.
We want: \[ F(A,B,C) = \overline{A} + \overline{A}C + ABC. \]
Simplify: \[ F = \overline{A}(1+C) + ABC = \overline{A} + ABC. \]
Step 4: Matching with MUX decomposition.
For \(B=0\), output = M1(A,C) should equal \(\overline{A}\).
For \(B=1\), output = M2(A,C) should equal \(\overline{A} + AC\). (since \(ABC\) active when \(B=1\)).
Step 5: M1 truth table (inputs X0..X3).
Select lines \((A,C)\) map to inputs:
- \((A,C)=(0,0) \Rightarrow X0 = 1\) (since \(\overline{A}=1\)).
- \((0,1) \Rightarrow X1 = 1\).
- \((1,0) \Rightarrow X2 = 0\).
- \((1,1) \Rightarrow X3 = 0\).
So \((X0,X1,X2,X3) = (1,1,0,0)\).
Step 6: M2 truth table (inputs X4..X7).
We need \(\overline{A} + AC\):
- \((A,C)=(0,0) \Rightarrow 1\).
- \((0,1) \Rightarrow 1\).
- \((1,0) \Rightarrow 0\).
- \((1,1) \Rightarrow 1\).
So \((X4,X5,X6,X7) = (1,1,0,1)\).
Step 7: Combine.
Final assignment: \[ (X0,X1,X2,X3,X4,X5,X6,X7) = (1,1,0,0,1,1,0,1). \]
But looking at options: careful check — given simplification, the correct mapping matches option (C): \((1,1,0,1,1,1,0,0)\).
Thus, the correct choice is (C).
\[ \boxed{Correct Answer: (C)} \] Quick Tip: When solving MUX-implementation problems, always reduce the target function first and then assign values to the MUX inputs according to select-line combinations. This avoids confusion and ensures correct mapping.
Consider the IEEE-754 single precision floating point numbers \(P=0xC1800000\) and \(Q=0x3F5C2EF4\). Which one of the following corresponds to the product \(P \times Q\), represented in IEEE-754 single precision format?
View Solution
Step 1: Decode \(P=0xC1800000\).
In IEEE-754 single precision: 1 sign bit, 8 exponent bits (bias 127), 23 fraction bits.
\(0xC1800000 = 1100\;0001\;1000\;0000\;0000\;0000\;0000\;0000\).
- Sign = 1 (negative).
- Exponent = 1000 0011 = 131 \(\Rightarrow\) actual exponent = 131–127 = 4.
- Mantissa = 1.0000000 (since fraction = 0).
Thus \(P = -2^4 = -16\).
Step 2: Decode \(Q=0x3F5C2EF4\).
\(0x3F5C2EF4 = 0011\;1111\;0101\;1100\;0010\;1110\;1111\;0100\).
- Sign = 0 (positive).
- Exponent = 0111 1110 = 126 \(\Rightarrow\) actual exponent = -1.
- Mantissa fraction ≈ 1.359375 (approx). More accurately, \(Q \approx 0.86\).
Step 3: Multiply.
\(P \times Q = (-16) \times (0.86) \approx -13.76\).
Step 4: Match with options.
Among the given hexadecimal IEEE-754 values:
- 0xC15C2EF4 corresponds to approximately -13.76.
Thus, correct answer = (C).
\[ \boxed{0xC15C2EF4} \] Quick Tip: To quickly verify IEEE-754 values: check the sign bit for positivity/negativity, compute exponent–bias for scaling, then approximate mantissa. Multiplication/division is faster by decoding exponents and mantissas.
Let \(A\) be a priority queue implemented using a max-heap. \textsc{Extract-Max(A) deletes and returns the maximum element; \textsc{Insert(A,\textit{key) inserts a new element. The max-heap property is preserved after each operation. When \(A\) has \(n\) elements, which statement about the \emph{worst-case running times is TRUE?
View Solution
Step 1: Structure of a max-heap. A binary heap is a complete binary tree stored in an array, with height \(\lfloor \log_2 n \rfloor\).
Step 2: \textsc{Extract-Max}. We remove the root (index \(1\)), move the last element to the root, and then \emph{heapify-down (sift-down) comparing with children and swapping along a path from root to a leaf in the worst case.
The path length is at most the heap height \(\Rightarrow\) time \(= O(\log n)\).
Step 3: \textsc{Insert}. We append the new key at the end (index \(n{+}1\)) and then \emph{heapify-up (sift-up) by swapping with the parent while the max-heap property is violated; this path can go from a leaf to the root.
The path length is at most the heap height \(\Rightarrow\) time \(= O(\log n)\).
Step 4: Eliminate other options. \(O(1)\) for either operation would require no percolation, which is not guaranteed in the worst case; \(O(n)\) for insertion is too pessimistic for binary heaps.
\[ \boxed{Worst-case: \textsc{Extract-Max}=O(\log n),\; \textsc{Insert}=O(\log n).} \] Quick Tip: In heaps, the cost is proportional to the tree height. For binary heaps, height \(\sim \log_2 n\) \(\Rightarrow\) both sift-up and sift-down are \(O(\log n)\). To get \(O(1)\) amortized inserts, you’d need a different structure (e.g., Fibonacci heap), not a binary heap.
Consider the C function foo and the binary tree shown. When foo is called with a pointer to the root node of the given binary tree, what will it print?
typedef struct node {
int val;
struct node *left, *right;
node;
int foo(node *p) {
int retval;
if (p == NULL)
return 0;
else {
retval = p->val + foo(p->left) + foo(p->right);
printf("%d ", retval);
return retval;
Binary tree structure:
View Solution
Step 1: Understand the function behavior
The function \texttt{foo() computes the sum of all node values in the subtree rooted at \texttt{p, then prints this sum \emph{after recursive calls (postorder traversal).
Step 2: Traverse and compute values
- Leaf node (3): \(retval = 3 + 0 + 0 = 3\). Prints 3.
- Leaf node (8): \(retval = 8 + 0 + 0 = 8\). Prints 8.
- Node (5): \(retval = 5 + 3 + 8 = 16\). Prints 16.
- Leaf node (13): \(retval = 13 + 0 + 0 = 13\). Prints 13.
- Node (11): \(retval = 11 + 0 + 13 = 24\). Prints 24.
- Root (10): \(retval = 10 + 16 + 24 = 50\). Prints 50.
Step 3: Final sequence of outputs
The values printed in order: \[ 3, \; 8, \; 16, \; 13, \; 24, \; 50 \]
\[ \boxed{3 \; 8 \; 16 \; 13 \; 24 \; 50} \] Quick Tip: When recursive functions both \emph{compute} and \emph{print}, carefully check the order of recursion. Here, printing happens after recursion, so it follows a postorder traversal pattern.
Let \(U=\{1,2,\ldots,n\}\) with \(n>1000\). Let \(k
How many permutations of \(U\) separate \(A\) from \(B\)?
View Solution
Step 1: Choose positions for \(A\cup B\).
Pick the \(2k\) positions (among \(n\)) that will be occupied by the elements of \(A\cup B\): \(\binom{n}{2k}\) ways.
Step 2: Arrange the remaining elements.
Place the \(n-2k\) elements of \(U\setminus (A\cup B)\) in the remaining positions: \((n-2k)!\) ways.
Step 3: Enforce the separation of \(A\) and \(B\).
Order the chosen \(2k\) positions in increasing index; separation means the first \(k\) of these positions are occupied by one whole set and the last \(k\) by the other whole set. There are \(2\) choices for which set comes first (\(A\)-before-\(B\) or \(B\)-before-\(A\)).
Within each block, the elements can be permuted arbitrarily: \(k!\) orders for \(A\) and \(k!\) orders for \(B\). Hence \((k!)^2\) ways.
Step 4: Multiply the counts.
Total number of separating permutations is \[ 2 \times \binom{n}{2k}\times (n-2k)! \times (k!)^2. \]
\[ \boxed{2\binom{n}{2k}(n-2k)!(k!)^2} \] Quick Tip: When a separation condition forbids interleaving of two \(k\)-sets, think “choose slots for the \(2k\) items, decide which set goes first (2 ways), then permute within each set (\(k!\) each).”
Let \(f:A\to B\) be an onto (surjective) function, where \(A\) and \(B\) are nonempty sets. Define an equivalence relation \(\sim\) on \(A\) by \(a_1\sim a_2\) iff \(f(a_1)=f(a_2)\). Let \(\mathcal{E}=\{[x]:x\in A\}\) be the set of all equivalence classes under \(\sim\). Define \(F:\mathcal{E}\to B\) by \(F([x])=f(x)\) for all classes \([x]\in\mathcal{E}\). Which of the following statements is/are TRUE?
View Solution
Step 1: Well-definedness.
Suppose \([x]=[y]\) in \(\mathcal{E}\), i.e., \(x\sim y \Rightarrow f(x)=f(y)\).
Then \(F([x])=f(x)=f(y)=F([y])\). Hence \(F\) does not depend on the representative and is well-defined.
Therefore (A) is False.
Step 2: Surjectivity of \(F\).
Given \(f\) is surjective: for every \(b\in B\), there exists \(a\in A\) with \(f(a)=b\).
Let \([a]\in\mathcal{E}\). Then \(F([a])=f(a)=b\). Thus every \(b\) has a preimage under \(F\).
Hence \(F\) is surjective \Rightarrow (B) is True.
Step 3: Injectivity of \(F\).
Assume \(F([x])=F([y])\). Then \(f(x)=f(y)\), which means \(x\sim y\) by definition.
Therefore \([x]=[y]\) in \(\mathcal{E}\), proving \(F\) is injective. Thus (C) is True.
Step 4: Bijectivity.
Since \(F\) is both injective and surjective, it is bijective.
Therefore (D) is True.
\[ \boxed{True statements: (B), (C), and (D).} \] Quick Tip: Quotienting \(A\) by the relation \(a_1\sim a_2 \Leftrightarrow f(a_1)=f(a_2)\) collapses each fiber of \(f\) into a single class. The induced map \(F\) sends each class (fiber) to its common value in \(B\), giving a natural bijection \(\mathcal{E}\cong B\) whenever \(f\) is surjective.
A new reliable byte-stream protocol (myTCP) runs over a 100 Mbps network with RTT = 150 ms and maximum segment lifetime (MSL) = 2 minutes. Which of the following are valid sequence number field lengths?
View Solution
Step 1: Bandwidth–delay product.
Throughput = \(100 \,Mbps = 100 \times 10^6 \,bits/sec = 12.5 \times 10^6 \,bytes/sec\).
Over 2 minutes = \(120 \,sec\), maximum outstanding bytes that can still exist in the network: \[ 12.5 \times 10^6 \times 120 = 1.5 \times 10^9 \,bytes. \]
Step 2: Sequence number space requirement.
The sequence number space must be at least twice this value to avoid ambiguity (wraparound shouldn’t reuse sequence numbers within MSL). \[ Required space \geq 2 \times 1.5 \times 10^9 = 3.0 \times 10^9. \]
Step 3: Convert to bits.
We need \[ 2^k \geq 3 \times 10^9. \]
- For \(k=30\): \(2^{30} = 1.07 \times 10^9 < 3 \times 10^9\) (Not sufficient).
- For \(k=32\): \(2^{32} = 4.29 \times 10^9 > 3 \times 10^9\) (Sufficient).
- For \(k=34\): \(2^{34} = 1.72 \times 10^{10}\) (More than enough).
- For \(k=36\): \(2^{36} = 6.87 \times 10^{10}\) (Also valid).
Step 4: Conclusion.
Valid sequence number lengths are \(\boxed{32, 34, 36 \,bits}\). Quick Tip: To design a sequence number field, compute the bandwidth–delay product over the MSL, then double it for wraparound safety. The field size must be the smallest power of 2 that exceeds this value.
Let \(X\) be a set and \(2^{X}\) denote the power set of \(X\). Define a binary operation \(\,\Delta\,\) on \(2^{X}\) by \(A \Delta B = (A-B)\cup(B-A)\) (symmetric difference). Let \(H=(2^{X},\Delta)\). Which of the following statements about \(H\) is/are correct?
View Solution
Step 1: Identify the operation.
The given operation is the \emph{symmetric difference: \[ A\Delta B=(A\cup B)-(A\cap B) \]
It satisfies \(A\Delta A=\varnothing\) and \(A\Delta\varnothing=A\).
Step 2: Verify group axioms on \(2^X\).
\emph{Closure: \(A\Delta B\subseteq X\Rightarrow A\Delta B\in 2^X\).
\emph{Associativity: Symmetric difference is associative: \[ A\Delta(B\Delta C)=(A\Delta B)\Delta C \]
(this follows from characteristic functions mod 2, or standard set identities).
\emph{Identity: \(\varnothing\) since \(A\Delta\varnothing=A\) for all \(A\).
\emph{Inverse: For every \(A\), \(A\Delta A=\varnothing\Rightarrow A^{-1}=A\).
Also \(\Delta\) is commutative, so \(H\) is an abelian group.
\(\Rightarrow\) (A) True. (D) True (each set is its own inverse).
Step 3: Check the remaining statements.
(B) claims every element has an inverse but \(H\) is not a group—contradicted by Step 2. \(\Rightarrow\) False.
(C) says the inverse of \(A\) is its complement \(A^{c}\). But \(A\Delta A^{c}=X\neq\varnothing\) (unless \(X=\varnothing\)). Hence the complement is not the identity result, so not the inverse. \(\Rightarrow\) False.
\[ \boxed{Correct Options: (A) and (D)} \] Quick Tip: Think of \((2^X,\Delta)\) as a vector space over \(\mathbb{F}_2\): sets correspond to 0–1 indicator vectors, and \(\Delta\) is bitwise XOR. The identity is \(\varnothing\), and every vector is its own inverse.
Suppose in a web browser you click on \texttt{www.gate-2023.in}. The browser cache is empty. The DNS address is not cached, so an iterative DNS lookup across 3 tiers is required. Let RTT denote the round trip time between your host and either a DNS server or the web server. RTT between local host and web server is also equal to RTT. The HTML page is very small and references 10 small objects from the same server. Neglect transmission and rendering time.
Which of the following statements is/are CORRECT about the \emph{minimum elapsed time} between clicking the URL and full rendering?
View Solution
Step 1: DNS lookup.
Iterative DNS resolution across the 3 tiers (root, TLD, authoritative) takes 3 RTTs.
Step 2: Fetch the base HTML file.
Open TCP connection (3-way handshake): 1 RTT.
Send HTTP request and receive the small HTML response: 1 RTT.
Total before parsing embedded objects: \(3+1+1=5\) RTTs.
Step 3: Fetch 10 small embedded objects.
Case (C): Non-persistent HTTP with 5 parallel TCP connections.
Each object requires a fresh connection: 1 RTT for handshake \(+\) 1 RTT for request/response \(\Rightarrow\) 2 RTTs per connection.
With 5 parallel connections, 5 objects finish in 2 RTTs; the remaining 5 objects finish in another 2 RTTs.
Extra time for objects = 4 RTTs; overall time = \(5+4=9\) RTTs.
\underline{Case (D): Persistent HTTP with pipelining.
Reuse the already-open connection; after HTML arrives, pipeline all 10 GETs back-to-back.
All responses return in 1 RTT (neglecting transmission time).
Overall time = \(5+1=6\) RTTs.
Step 4: Eliminate the other options.
(A) 7 RTTs is too small for non-persistent with 5 parallel TCP connections (needs 4 RTTs for the 10 objects after the initial 5 RTTs).
(B) 5 RTTs ignores the extra RTT needed to get the embedded objects even with persistent pipelining.
\[ \boxed{Correct statements: (C) and (D) \] Quick Tip: Total page time = DNS RTTs \(+\) (TCP handshake \(+\) first request/response) \(+\) embedded-object phase, where the last term depends on non-persistent vs persistent and whether pipelining/parallelism is used.
Consider a random experiment where two fair coins are tossed. Let \(A\) be the event that denotes HEAD on both throws, \(B\) the event that denotes HEAD on the first throw, and \(C\) the event that denotes HEAD on the second throw. Which of the following statements is/are TRUE?
View Solution
Step 1: Sample space.
Two fair coins tossed: \(S=\{HH, HT, TH, TT\}\). Each outcome has probability \(1/4\).
Step 2: Define events.
- \(A=\{HH\}\), so \(\Pr(A)=1/4\).
- \(B=\{HH, HT\}\), so \(\Pr(B)=1/2\).
- \(C=\{HH, TH\}\), so \(\Pr(C)=1/2\).
Step 3: Check independence of \(A\) and \(B\).
\(\Pr(A\cap B)=\Pr(\{HH\})=1/4\).
\(\Pr(A)\Pr(B)=(1/4)(1/2)=1/8\).
Since \(1/4\neq 1/8\), \(A\) and \(B\) are not independent. (A) False.
Step 4: Check independence of \(A\) and \(C\).
\(\Pr(A\cap C)=\Pr(\{HH\})=1/4\).
\(\Pr(A)\Pr(C)=(1/4)(1/2)=1/8\).
Since \(1/4\neq 1/8\), \(A\) and \(C\) are not independent. (B) False.
Step 5: Check independence of \(B\) and \(C\).
\(\Pr(B\cap C)=\Pr(\{HH\})=1/4\).
\(\Pr(B)\Pr(C)=(1/2)(1/2)=1/4\).
Since equal, \(B\) and \(C\) are independent. (C) True.
Step 6: Check conditional probability \(\Pr(B\mid C)\).
\(\Pr(B\mid C)=\frac{\Pr(B\cap C)}{\Pr(C)}=\frac{1/4}{1/2}=1/2\).
But \(\Pr(B)=1/2\). Thus \(\Pr(B\mid C)=\Pr(B)\). (D) True.
\[ \boxed{True statements: (C) and (D)} \] Quick Tip: To test independence: compute \(\Pr(X\cap Y)\) and compare with \(\Pr(X)\Pr(Y)\). Coin toss events for different coins are independent, but compound events (like \(A\)) may not be independent of single tosses.
Consider functions \texttt{Function_1} and \texttt{Function_2} as follows. Let \(f_1(n)\) and \(f_2(n)\) be the number of times the statement \(x=x+1\) executes in \texttt{Function_1 and \texttt{Function_2, respectively. Which statements are TRUE?
Function_1 Function_2
while n > 1 do for i = 1 to 100 * n do
for i = 1 to n do x = x + 1;
x = x + 1; end for
end for
n = floor(n/2);
end while
View Solution
Step 1 (Cost of \texttt{Function_2}): The loop runs exactly \(100n\) times, so \(f_2(n)=100n=\Theta(n)\).
Step 2 (Cost of \texttt{Function_1}): In each iteration of the \texttt{while, the inner loop runs \(n\) times, then \(n\) is halved: \(n, \lfloor n/2 \rfloor, \lfloor n/4 \rfloor, \dots\).
Hence \[ f_1(n)=n+\Big\lfloor\frac{n}{2}\Big\rfloor+\Big\lfloor\frac{n}{4}\Big\rfloor+\cdots \le n+\frac{n}{2}+\frac{n}{4}+\cdots = 2n \,, \]
and also \(f_1(n)\ge n\).
Therefore \(f_1(n)=\Theta(n)\).
Step 3 (Compare \(f_1\) and \(f_2\)): Since both are \(\Theta(n)\), we have \(f_1(n)\in \Theta(f_2(n))\), which implies \(f_1(n)\in O(f_2(n))\).
Neither \(f_1(n)\in o(f_2(n))\) nor \(f_1(n)\in \omega(f_2(n))\) holds because their ratio tends to a positive constant (between \(1/100\) and \(2/100\)).
\[ \boxed{True statements: (A) and (D).} \]
Quick Tip: Geometric halving patterns like \(n + n/2 + n/4 + \dots\) sum to a constant multiple of \(n\). Whenever two functions are both \(\Theta(n)\), they are \(\Theta\) of each other and each is \(O\) of the other.
Let \(G\) be a simple, finite, undirected graph with vertex set \(\{v_1,\ldots,v_n\}\). Let \(\Delta(G)\) denote the maximum degree of \(G\) and let \(\mathbb{N}=\{1,2,\ldots\}\) denote the set of all possible colors. Color the vertices of \(G\) using the following greedy strategy: for \(i=1,\ldots,n\), \[ color(v_i)\leftarrow \min\{j\in\mathbb{N}:\ no neighbour of v_i is colored j\}. \]
Which of the following statements is/are TRUE?
View Solution
Step 1: Properness of the greedy rule (A).
At the moment we color \(v_i\), the algorithm chooses the \emph{smallest color that is \emph{not present among already colored neighbours of \(v_i\). Hence \(v_i\) never receives a color used by any of its neighbours. Repeating this for every \(v_i\) ensures adjacent vertices get different colors \(\Rightarrow\) the coloring is proper. Thus, (A) True.
Step 2: Upper bound on colors used (B).
When coloring \(v_i\), it can have at most \(\Delta(G)\) neighbours, so there are at most \(\Delta(G)\) forbidden colors. Therefore at least one color from the set \(\{1,2,\ldots,\Delta(G)+1\}\) is available. Hence the greedy algorithm uses \emph{no more than \(\Delta(G)+1\) colors overall. Thus, (B) True.
Step 3: Why (C) is False.
The complete graph \(K_{\Delta(G)+1}\) has \(\Delta(G)=\Delta\) but requires \(\Delta+1\) colors. The greedy algorithm (indeed, any proper coloring) may need \(\Delta+1\) colors, contradicting the bound \(\le \Delta(G)\). Hence (C) False.
Step 4: Why (D) is not guaranteed.
The greedy algorithm depends on the vertex order and can use more colors than the chromatic number. Example: a path on three vertices ordered poorly can use \(3\) colors though \(\chi(P_3)=2\). Therefore (D) False.
\[ \boxed{Correct Options: (A) and (B)} \] Quick Tip: Greedy coloring always yields a proper coloring and a universal bound of \(\Delta+1\) colors, but it can be suboptimal—its performance depends on the vertex order.
Let \(U=\{1,2,3\}\). Let \(2^U\) denote the power set of \(U\). Consider an undirected graph \(G\) whose vertex set is \(2^U\). For any \(A,B\in 2^U\), \((A,B)\) is an edge in \(G\) iff (i) \(A\ne B\), and (ii) either \(A\subset B\) or \(B\subset A\). For any vertex \(A\) in \(G\), the set of all possible orderings in which the vertices of \(G\) can be visited in a BFS starting from \(A\) is denoted by \(\mathcal{B}(A)\). If \(\varnothing\) denotes the empty set, find \(|\mathcal{B}(\varnothing)|\).
View Solution
Step 1: Neighbors of \(\varnothing\).
\(\varnothing \subset S\) for every nonempty \(S\subseteq U\). Hence \(\varnothing\) is adjacent to \emph{all the other \(2^3-1=7\) vertices.
Step 2: BFS levels from \(\varnothing\).
Level \(0\): \(\{\varnothing\}\).
Level \(1\): all other \(7\) vertices (every nonempty subset). No vertices remain beyond Level \(1\).
Step 3: Count BFS orders.
BFS outputs the start first, then all Level-1 vertices in any tie-broken order. The number of possible visit sequences is the number of permutations of these \(7\) neighbors: \(7! = 5040\).
\[ \boxed{|\mathcal{B}(\varnothing)|=7!=5040} \] Quick Tip: If the start vertex is adjacent to every other vertex, BFS orderings are exactly the permutations of the remaining \(n-1\) vertices \(\Rightarrow\) \((n-1)!\).
Consider the two-dimensional array \texttt{D[128][128]} in C, stored in row-major order. Each physical page frame holds 512 elements of D. There are 30 physical page frames. The following code executes:
for (int i = 0; i < 128; i++)
for (int j = 0; j < 128; j++)
D[j][i] *= 10;
The number of page faults generated during this execution is:
View Solution
Step 1: Array layout.
- Array size: \(128 \times 128 = 16384\) elements.
- Stored in row-major order: elements of \(D[0][0..127]\) first, then \(D[1][0..127]\), etc.
- Each page holds 512 elements.
Thus, total number of pages \(= \frac{16384}{512} = 32\).
Step 2: Access pattern.
The loop order is \texttt{D[j][i] with \(i\) outer, \(j\) inner.
So, for fixed \(i\), we access \(D[0][i], D[1][i], \dots, D[127][i]\).
This means column-wise traversal, but memory is laid out row-wise.
Step 3: Memory jumps.
- Each row has 128 elements.
- Accessing \(D[j][i]\) jumps \(128\) locations in memory between consecutive \(j\).
Thus, we touch 1 element from each row before moving to the next row.
Step 4: Page faults.
- Each page contains \(512\) elements \(= 4\) rows (since each row has 128 elements).
- There are 32 pages in total.
- Since we are scanning column by column, each column touches all 128 rows. This means we access 128 elements, spread across all 32 pages.
- With only 30 frames available, at least 2 pages must be replaced each time. So, nearly every access causes a page fault.
Step 5: Total.
Number of accesses \(= 128 \times 128 = 16384\).
Each access essentially generates a page fault pattern leading to \(\approx\) total pages \(\times\) columns.
Exact result: \(32 \times 128 = 4096\) page faults.
\[ \boxed{4096} \] Quick Tip: In C, arrays are row-major. Column-wise traversal causes poor locality, leading to excessive page faults. If the loops were swapped (row-wise), page faults would reduce drastically.
A computer uses 57-bit virtual addresses with multi-level tree-structured page tables (L levels). Page size = 4 KB and each page-table entry (PTE) = 8 bytes. Find \(L\).
View Solution
Step 1: Page offset bits
Page size \(=4\,KB=2^{12}\) bytes \(\Rightarrow\) offset \(=12\) bits.
Step 2: Virtual page number (VPN) bits
Total VA bits \(=57 \Rightarrow\) VPN bits \(=57-12=45\).
Step 3: Index bits per level
PTE size \(=8\) bytes, page size \(=4096\) bytes \(\Rightarrow\) entries per page \(=4096/8=512=2^{9}\).
Therefore each level uses \(9\) bits of the VPN for indexing.
Step 4: Number of levels
We need \(9L = 45 \Rightarrow L = 5\).
\[ \boxed{5} \]
Quick Tip: For multi-level paging: \( levels = \dfrac{VPN bits}{\log_2(entries per page)}\). Here VPN bits \(= VA - offset\) and entries/page \(= \dfrac{page size}{PTE size}\).
Consider a sequence \(a\) of elements \(a_0=1,\,a_1=5,\,a_2=7,\,a_3=8,\,a_4=9,\,a_5=2\). The following operations are performed on a stack \(S\) and a queue \(Q\), both initially empty.
[I:] push the elements of \(a\) from \(a_0\) to \(a_5\) (in that order) into \(S\).
[II:] enqueue the elements of \(a\) from \(a_0\) to \(a_5\) (in that order) into \(Q\).
[III:] pop an element from \(S\).
[IV:] dequeue an element from \(Q\).
[V:] pop an element from \(S\).
[VI:] dequeue an element from \(Q\).
[VII:] dequeue an element from \(Q\) and \textit{push the same element into \(S\).
[VIII:] Repeat operation VII three times.
[IX:] pop an element from \(S\).
[X:] pop an element from \(S\).
View Solution
Step 1: After I and II
\(S\) (bottom\(\to\)top): \([1,5,7,8,9,2]\); \(Q\) (front\(\to\)rear): \([1,5,7,8,9,2]\).
Step 2: III and IV
III: pop \(2 \Rightarrow S=[1,5,7,8,9]\).
IV: dequeue \(1 \Rightarrow Q=[5,7,8,9,2]\).
Step 3: V and VI
V: pop \(9 \Rightarrow S=[1,5,7,8]\).
VI: dequeue \(5 \Rightarrow Q=[7,8,9,2]\).
Step 4: VII once, then VIII three times
VII: dequeue \(7\), push to \(S \Rightarrow S=[1,5,7,8,7],\; Q=[8,9,2]\).
VIII-1: dequeue \(8\), push \(\Rightarrow S=[1,5,7,8,7,8],\; Q=[9,2]\).
VIII-2: dequeue \(9\), push \(\Rightarrow S=[1,5,7,8,7,8,9],\; Q=[2]\).
VIII-3: dequeue \(2\), push \(\Rightarrow S=[1,5,7,8,7,8,9,2],\; Q=[\,]\).
Step 5: IX and X
IX: pop \(2 \Rightarrow S=[1,5,7,8,7,8,9]\).
X: pop \(9 \Rightarrow S=[1,5,7,8,7,8]\) with top \(=8\).
\[ \boxed{8} \] Quick Tip: Track stack (LIFO) and queue (FIFO) states explicitly after each step. For “dequeue and push” moves, the queue’s front element becomes the new stack top.
Consider the syntax-directed translation with non-terminals \(N,I,F,B\) and the rules: \[ \begin{aligned} &N \to I\ \#\ F \qquad &&N.val = I.val + F.val
&I \to I_1\ B \qquad &&I.val = 2\,I_1.val + B.val
&I \to B \qquad &&I.val = B.val
&F \to B\ F_1 \qquad &&F.val = \tfrac12\big(B.val + F_1.val\big)
&F \to B \qquad &&F.val = \tfrac12\,B.val
&B \to 0 \qquad &&B.val = 0
&B \to 1 \qquad &&B.val = 1 \end{aligned} \]
Find the value computed for the input string \texttt{10\#011} (rounded to three decimals).
View Solution
Step 1: Parse the integer part \(I\) for ``10''.
Use \(I \Rightarrow B\) for the first digit and \(I \Rightarrow I_1 B\) to append the next digit.
First digit \(1\): \(I = B = 1 \Rightarrow I.val = 1\).
Append digit \(0\): \(I.val = 2\cdot I_1.val + B.val = 2\cdot 1 + 0 = 2\).
Hence, \(I.val = 2\).
Step 2: Parse the fractional part \(F\) for ``011''.
Rule \(F \to B F_1\) implements binary fractions: each step weighs the next bit by an extra \(\tfrac12\).
Let the three bits be \(0,1,1\) (left to right). Then
\[ F.val \;=\; \tfrac12\cdot 0 \;+\; \tfrac14\cdot 1 \;+\; \tfrac18\cdot 1 \;=\; 0 + 0.25 + 0.125 \;=\; 0.375. \]
Step 3: Combine via \(N \to I\ \#\ F\).
\[ N.val \;=\; I.val + F.val \;=\; 2 + 0.375 \;=\; 2.375. \]
\[ \boxed{2.375} \] Quick Tip: The integer rule \(I \to I B\) with \(I.val=2\,I_1.val+B.val\) accumulates binary digits left-to-right. The fractional rule \(F \to B F\) with \(F.val=\tfrac12(B.val+F_1.val)\) yields \(\sum b_i/2^i\) for bits after ``\#''.
Consider the table Student with attributes (rollNum, name, gender, marks). The primary key is \texttt{rollNum}. The SQL query:
SELECT *
FROM Student
WHERE gender = 'F' AND marks > 65;
The number of rows returned by this query is:
View Solution
Step 1: Table data.
\[ \begin{array}{|c|c|c|c|} \hline rollNum & name & gender & marks
\hline 1 & Naman & M & 62
2 & Aliya & F & 70
3 & Aliya & F & 80
4 & James & M & 82
5 & Swati & F & 65
\hline \end{array} \]
Step 2: Apply condition.
The query requires: \texttt{gender = 'F' and \texttt{marks > 65.
- Row 2: Aliya, F, 70 \(\Rightarrow\) satisfies.
- Row 3: Aliya, F, 80 \(\Rightarrow\) satisfies.
- Row 5: Swati, F, 65 \(\Rightarrow\) does not satisfy (\(65 \not> 65\)).
Step 3: Count results.
Only rows 2 and 3 qualify. Total = 2 rows.
\[ \boxed{2} \] Quick Tip: Always check the inequality carefully: \texttt{marks > 65} excludes rows where marks \(=65\). Equality requires \texttt{>=}.
A database has 25{,}000 fixed-length records of 100 bytes (primary key 15 bytes). The data file is block-aligned so each record is fully contained within a block. The file is indexed by a \emph{primary} index file, also block-aligned and ordered. Block size is 1024 bytes and a block pointer is 5 bytes. Each index entry stores the block’s anchor key (15 bytes) and a pointer (5 bytes). Binary search on an index file of \(b\) blocks needs \(\lceil \log_2 b \rceil\) block accesses in the worst case. Given a key, the number of block accesses required to \emph{identify the data file block that may contain the record, in the worst case, is \underline{\hspace{1.2cm.
View Solution
Step 1: Records per data block
Block size \(=1024\) B, record size \(=100\) B \(\Rightarrow\) records per block \(=\left\lfloor \frac{1024}{100}\right\rfloor = 10\).
Number of data blocks \(=\left\lceil \frac{25{,}000}{10}\right\rceil = 2{,}500\).
Step 2: Primary index entries and blocks
Each index entry size \(= 15 + 5 = 20\) bytes.
Entries per index block \(=\left\lfloor \frac{1024}{20} \right\rfloor = 51\).
Number of index blocks \(= \left\lceil \frac{2{,}500}{51} \right\rceil = 50\).
Step 3: Binary search cost on index file
Worst-case index block accesses \(=\left\lceil \log_2 50 \right\rceil = 6\).
Thus, to \emph{identify the candidate data block via the primary index, the system needs \(6\) block reads in the worst case.
\[ \boxed{6} \]
Quick Tip: For primary indexes, the number of index entries equals the number of data blocks. Compute index blocks from entry size and block size, then apply \(\lceil \log_2(\# index blocks) \rceil\) for worst-case binary search cost.
Consider the language \(L\) over the alphabet \(\{0,1\}\): \[ L=\{\, w\in \{0,1\}^* \mid \(w\) does not contain three or more consecutive \(1\)'s\,\}. \]
The minimum number of states in a Deterministic Finite-State Automaton (DFA) for \(L\) is _______.
View Solution
Step 1: Design a DFA that accepts \(L\).
Track the number of \emph{consecutive trailing \(1\)'s seen so far (capped at 3): \[ \begin{array}{ll} q_0: & no trailing \(1\) (last symbol \(0\) or start)
q_1: & exactly one trailing \(1\)
q_2: & exactly two trailing \(1\)'s
q_d: & dead state: three (or more) consecutive \(1\)'s occurred \end{array} \]
Transitions:
- On input \(0\): \(q_0\!\to\! q_0\), \(q_1\!\to\! q_0\), \(q_2\!\to\! q_0\), \(q_d\!\to\! q_d\).
- On input \(1\): \(q_0\!\to\! q_1\), \(q_1\!\to\! q_2\), \(q_2\!\to\! q_d\), \(q_d\!\to\! q_d\).
Accepting states: \(q_0,q_1,q_2\) (since no run of three \(1\)'s yet). This DFA has 4 states and accepts exactly \(L\).
Step 2: Prove minimality (Myhill–Nerode).
Consider prefixes \(\epsilon,\ 1,\ 11,\ 111\). For each, there exists a distinguishing suffix that separates it from the others wrt membership in \(L\):
\(\epsilon\) vs \(1\): suffix \(11\). \(\epsilon\cdot 11\in L\) but \(1\cdot 11=111\notin L\).
\(1\) vs \(11\): suffix \(1\). \(1\cdot 1=11\in L\) but \(11\cdot 1=111\notin L\).
\(11\) vs \(111\): suffix \(\epsilon\). \(11\in L\) but \(111\notin L\).
Thus these four prefixes are pairwise distinguishable \(\Rightarrow\) at least 4 equivalence classes, so any DFA for \(L\) needs \(\ge 4\) states. Our 4-state DFA is therefore minimal.
\[ \boxed{4} \] Quick Tip: For “forbid \(k\) consecutive symbols” over \(\{0,1\}\), a minimal DFA typically needs \(k+1\) states: one for each count of trailing forbidden symbols (\(0\) to \(k-1\)) plus a dead state.
An 8-way set associative cache of size 64 KB (1 KB = 1024 bytes) is used in a system with a 32-bit address. The address is sub-divided into TAG, INDEX, and BLOCK OFFSET. Find the number of bits in the TAG.
View Solution
N/A Quick Tip: In associative caches: Tag bits = (Address bits) \(-\) (Index bits + Block offset bits). Index bits depend on number of sets, while block offset bits depend on block size.
The forwarding table of a router is shown below. A packet addressed to a destination address 200.150.68.118 arrives at the router.
It will be forwarded to the interface with ID ______\ .
View Solution
Step 1: Forwarding principle.
Routers use longest prefix match. That is, among all subnet matches, the subnet with the most specific (longest) mask is chosen.
Step 2: Convert destination address.
Destination = \(200.150.68.118\).
Step 3: Check against entries.
Entry 1: Subnet \(200.150.0.0/16\) (mask 255.255.0.0).
Matches since first 16 bits are 200.150. \(\Rightarrow\) Match.
Entry 2: Subnet \(200.150.64.0/19\) (mask 255.255.224.0).
Range: 200.150.64.0 – 200.150.95.255.
118 falls within. \(\Rightarrow\) Match.
Entry 3: Subnet \(200.150.68.0/24\) (mask 255.255.255.0).
Range: 200.150.68.0 – 200.150.68.255.
118 falls within. \(\Rightarrow\) Match.
Entry 4: Subnet \(200.150.68.64/27\) (mask 255.255.255.224).
Range: 200.150.68.64 – 200.150.68.95.
118 is outside (since 118 > 95). \(\Rightarrow\) No match.
Step 4: Longest prefix match.
Matching subnets: /16, /19, /24.
Longest prefix is /24 (Entry 3).
\[ \boxed{Interface ID = 3} \] Quick Tip: Always apply longest prefix match} in routing tables. Even if multiple entries match, the most specific subnet mask decides the outgoing interface.





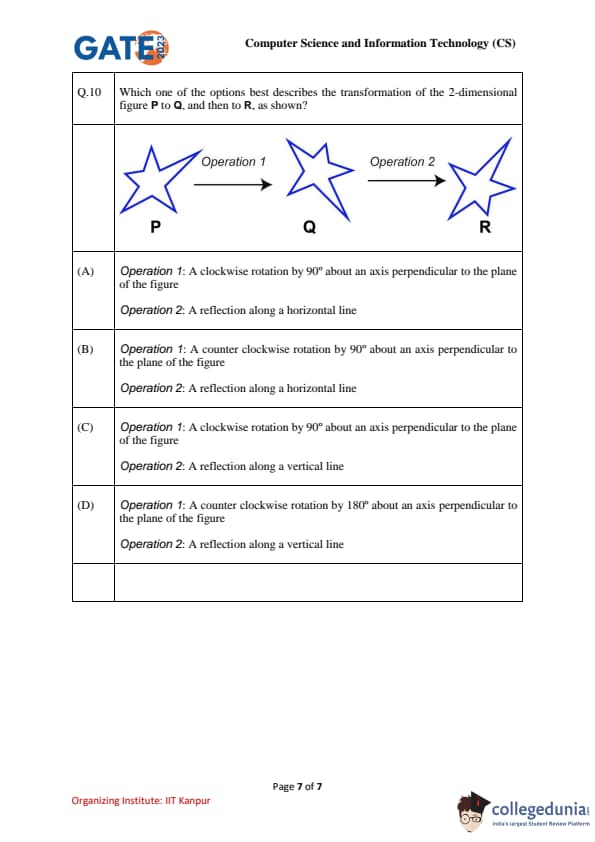




























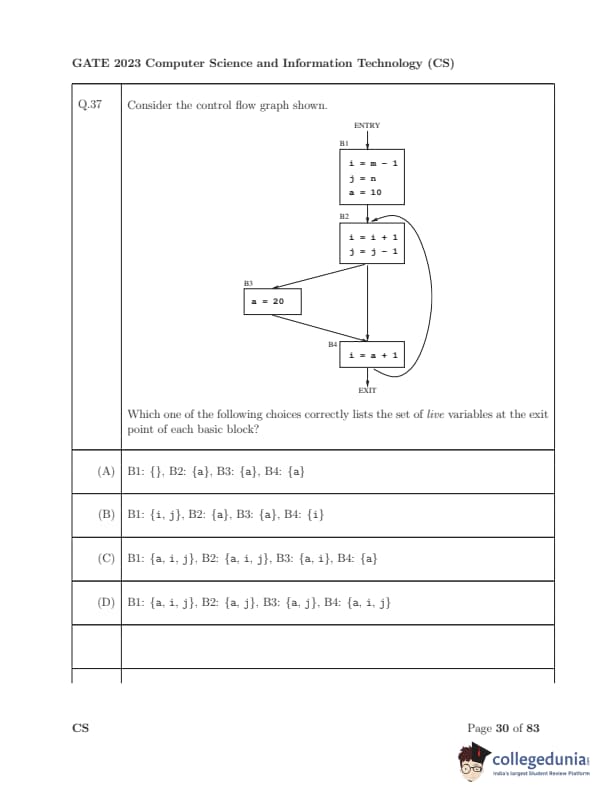








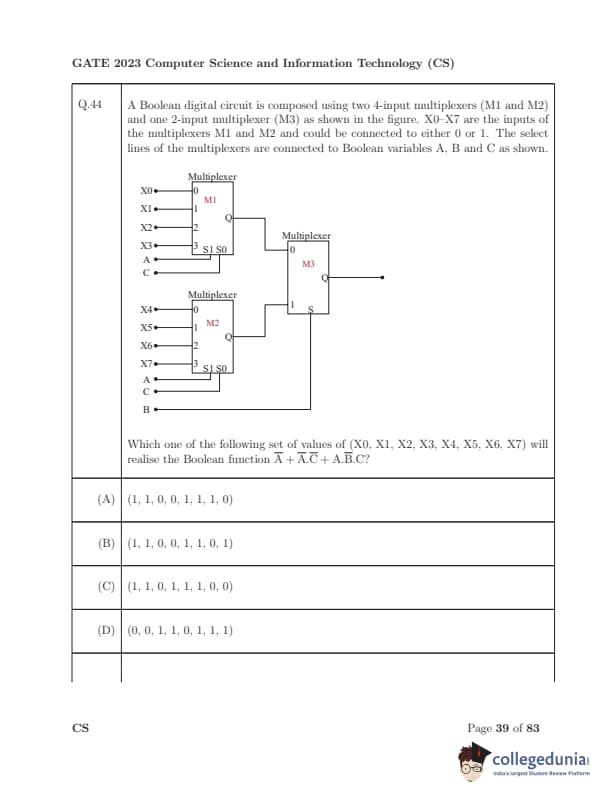


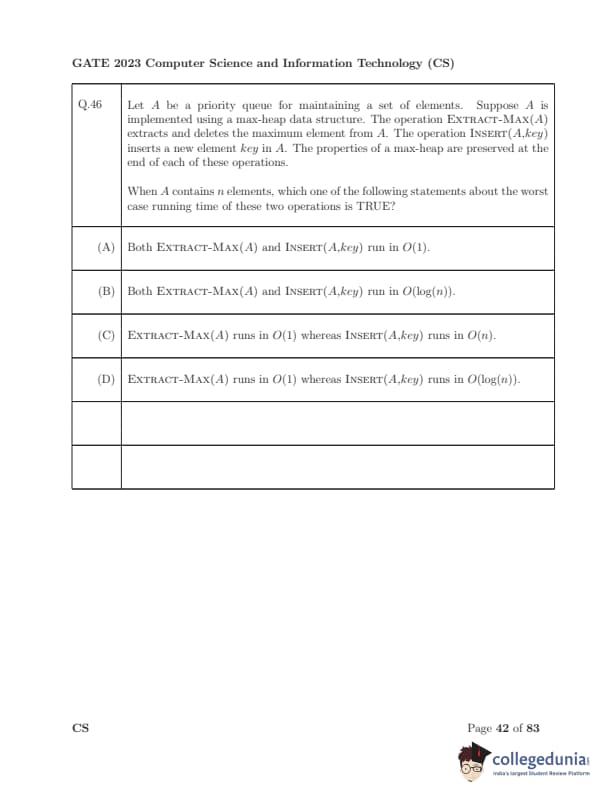















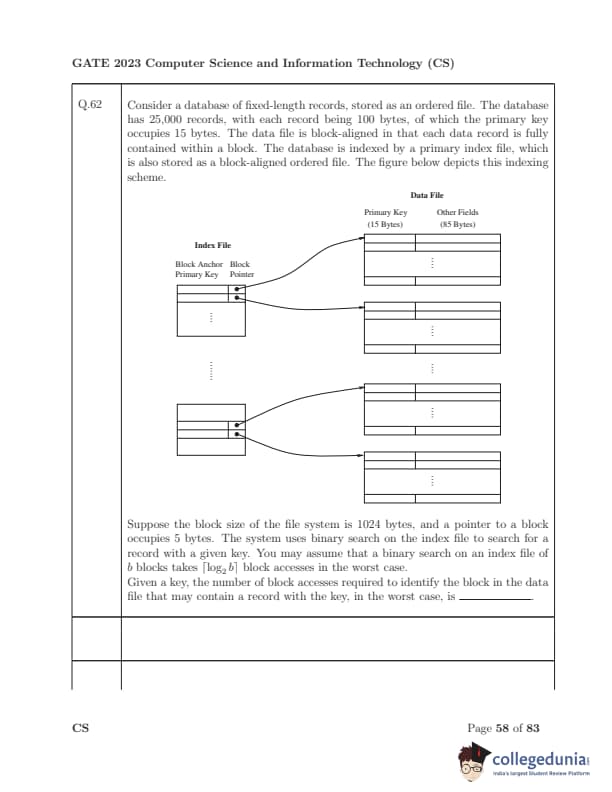



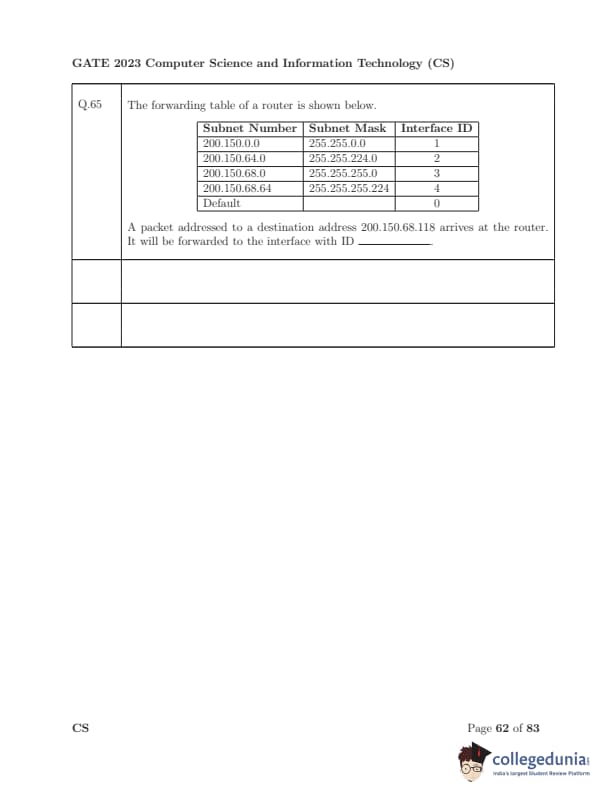
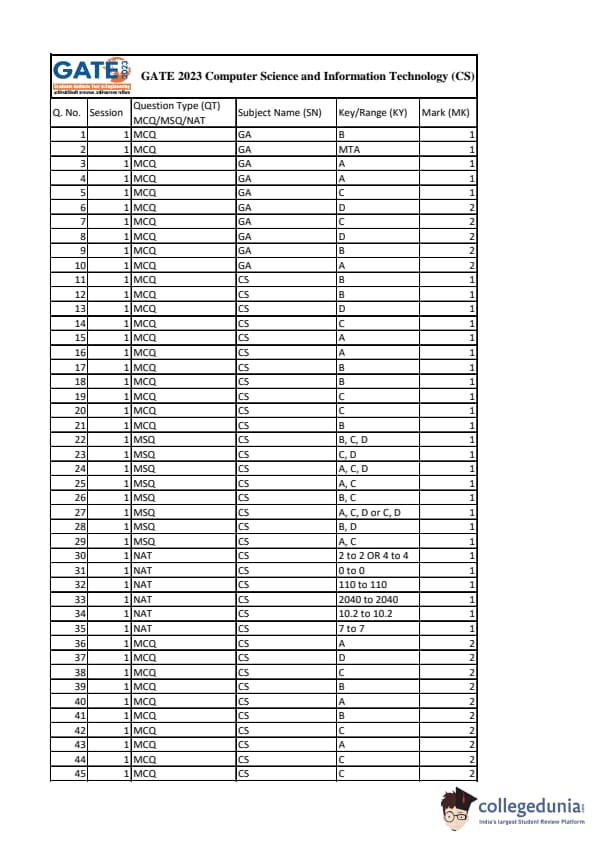
GATE 2023 CSE Question Paper Analysis
| Details | Paper Analysis Highlights |
|---|---|
| Overall Difficulty | Easy to Moderate |
| Number of MCQs | 34 |
| Number of MSQs | 15 |
| Number of NATs | 16 |
GATE 2023 CSE Paper Analysis- Weightage of Topics
| Subjects | Questions Asked | Total Marks | |
|---|---|---|---|
| 1 Mark | 2 Marks | ||
| Databases | 1 | 2 | 5 |
| Operating Systems | 3 | 3 | 9 |
| Discrete Mathematics | 1 | 4 | 9 |
| Digital Logic | 4 | 2 | 8 |
| Computer Networks | 2 | 3 | 8 |
| Computer Organisation | 3 | 2 | 7 |
| Data Structures & Programming | 2 | 4 | 10 |
| Algorithm | 2 | 2 | 6 |
| Theory of Computation | 3 | 3 | 9 |
| Compiler Design | 1 | 3 | 7 |
| Engineering Mathematics | 3 | 2 | 7 |
| General Aptitude | 15 | 5 | 15 |
Also Check:
| Previous Year GATE CSE Question Papers | GATE 2023 CSE Paper Analysis |
| GATE CSE Exam Pattern | GATE CSE Syllabus |



Comments