Senior Chemistry Editor | M.Sc. Chemistry, 12 Years | Updated on - May 25, 2026
The 2026-27 NCERT retains Chapter 10 Biomolecules in full, keeping all four pillars - carbohydrates, proteins, nucleic acids, and vitamins - while trimming the older "Hormones" sub-section. The chapter contributes 3 to 5 marks to the CBSE Class 12 Chemistry paper and is a frequent NEET hunting ground for assertion-reason questions. This page hosts the complete solutions PDF and the 2025 PYQ map.
These NCERT Solutions are curated by chemistry educators with NEET-PG mentoring experience, mapped to the 2026-27 syllabus, and refined against the last five years of CBSE, JEE Main, and NEET papers.
Biomolecules is the bridge chapter between organic Chemistry and Class 12 Biology, so the solutions on this page treat every answer like a viva: each functional group is named, every glycosidic linkage is drawn, and every assertion-reason question gets the reasoning written in full.
Why Biomolecules is the Easiest 5-Mark Block of Class 12 Chemistry
Unlike the rest of the organic unit, Biomolecules is largely memory-driven: there are no mechanisms to draw, no arrow-pushing, and the named reactions are limited to three transformations of glucose (acetylation, oxidation with HNO3, and reduction with HI). A student who has memorised the open-chain and cyclic structures of glucose plus the four levels of protein structure will recover almost the entire chapter's marks in under two days of revision.
What makes the chapter score is its predictability: CBSE has asked variants of "differentiate between starch and cellulose" in 2019, 2022, 2023, and 2024. Memorising the eight standard differentiation pairs from this chapter is a higher return per minute than any other Class 12 Chemistry exercise.
Watch Out: The 2026-27 NCERT dropped the detailed hormone classification sub-section, but Exemplar problems on hormones still appear in older question banks. If you are using a pre-2023 question paper for revision, skip the hormone questions, you will not see them in CBSE 2027.
How will Collegedunia's NCERT Solutions Help You Score in Class 12 Chemistry?
The Collegedunia solution set is designed to neutralise the chapter's two trap zones: open-chain versus cyclic structure conversions, and the secondary-structure terminology of proteins. Each solution explicitly states which carbon is the anomeric centre, which protein bond is the peptide bond, and which hydrogen bond stabilises which secondary structure.
Three habits this resource builds:
Structural fluency: open-chain Fischer projection, Haworth projection, and chair conformation of glucose are drawn side by side in three exercise solutions, with the C1 anomeric configuration explicitly labelled in each.
Distinction-table recall: every differentiation question (starch vs cellulose, DNA vs RNA, alpha-helix vs beta-pleated sheet, essential vs non-essential amino acids) is answered as a two-column table with the exact six points CBSE awards marks for.
Vitamin and enzyme tagging: the solutions colour-code vitamins by solubility (yellow = fat-soluble, blue = water-soluble) so the reader builds the table visually as they revise.
Quick Tip: Write the "FAD KEC" mnemonic (Fat-soluble: A, D, E, K) at the top of your answer sheet before you start the Biomolecules question. It saves you the 30 seconds of recall doubt that catches most students on vitamin questions.
Section 10.1 contributes 8 of the 24 main-exercise solutions on this page, anchored by carbohydrate classification, glucose open-chain and Haworth structure, the alpha and beta anomers, mutarotation, and the difference between glucose and fructose. Every Collegedunia solution names the aldohexose vs ketohexose distinction first, then locks in the pyranose (6-ring) vs furanose (5-ring) cyclisation step where most students drop marks.
Carbohydrate classification: monosaccharides (glucose, fructose, ribose, galactose) cannot be hydrolysed further; oligosaccharides (sucrose, maltose, lactose) yield 2-10 monosaccharide units on hydrolysis; polysaccharides (starch, cellulose, glycogen) yield more than 10. The solutions PDF draws the full classification tree on the first page of the carbohydrate block.
Open-chain glucose: aldohexose, C6H12O6, four chiral carbons C2-C5, D-(+) configuration. The six chemical evidences (Br2/H2O gives gluconic acid, HNO3 gives saccharic acid, acetic anhydride gives pentaacetate, HI heating gives n-hexane, NH2OH gives oxime, HCN gives cyanohydrin) prove the -CHO, five -OH and the straight 6-C chain.
Haworth projection and anomers: the C5-OH attacks the C1 -CHO to give a 6-membered pyranose ring with a new chiral centre at C1, the anomeric carbon. Alpha-D-glucose has -OH below the ring at C1, beta-D-glucose has -OH above the ring. The two are called anomers because they differ only at the anomeric C; everything else in the ring is identical.
Mutarotation: a pure anomer of glucose dissolved in water slowly equilibrates with the other anomer via the open-chain form. Specific rotation: pure alpha = +112 degrees, pure beta = +19 degrees, equilibrium mixture = +52.5 degrees. Epimers (e.g. glucose vs galactose at C4, glucose vs mannose at C2) differ at one non-anomeric chiral centre; do not confuse them with anomers.
Fructose structure: ketohexose with -C=O at C2; cyclises by C5-OH attacking C2 to give a 5-membered furanose ring. D-(-) configuration (laevorotatory, [alpha] = -92.4 degrees), in contrast to D-(+)-glucose - this disproves the older textbook claim that "D always means dextrorotatory".
Sucrose, Maltose, Lactose and Polysaccharide Linkages - Section 10.1.3 to 10.1.4 Solutions
Six exercise solutions on this page deal with disaccharide and polysaccharide structure. The two highest-yield concepts CBSE keeps recycling are the sucrose hydrolysis / invert sugar behaviour and the alpha-1,4 vs beta-1,4 linkage swap between starch and cellulose.
Indigestible to humans (no cellulase); ruminants ferment via gut bacteria
Glycogen ("animal starch")
alpha-D-glucose; like amylopectin but branches every ~10 residues
Non-reducing
Glycogen phosphorylase → glucose-1-phosphate (in liver and muscle)
Sucrose hydrolysis (invert sugar): sucrose + H2O → D-(+)-glucose + D-(-)-fructose; the specific rotation flips from +66.5 to -39.9 (glucose +52.5 + fructose -92.4) - hence the name "invert sugar". Honey, jams, and most soft-drinks are sweetened with invert sugar because it is sweeter than sucrose and resists crystallisation.
Amino Acids, Zwitterions and the Four Levels of Protein Structure - Section 10.2 Solutions
Five exercise solutions cover Section 10.2 (proteins). The most-asked sub-concepts are the zwitterion / isoelectric point, the peptide bond, and the primary, secondary, tertiary, quaternary classification. NCERT 2026-27 retains all four structure levels, the 20-amino-acid grid, and the essential / non-essential split.
Alpha-amino acid general formula: R-CH(NH2)-COOH. All 20 standard amino acids are alpha; only glycine (R = H) is achiral. Essential amino acids (NCERT count = 10): Valine, Leucine, Isoleucine, Threonine, Lysine, Methionine, Phenylalanine, Tryptophan, Histidine, Arginine - the body cannot synthesise them, they must come from diet.
Zwitterion: R-CH(+NH3)-COO-; net charge zero, amphoteric in water. The pH at which the net charge is exactly zero is the isoelectric point (pI); for neutral amino acids pI = (pKa1 + pKa2)/2. Zwitterion formation explains the unusually high melting points and high water solubility of free amino acids.
Peptide bond: the -COOH of one amino acid condenses with the -NH2 of the next, releasing H2O and forming a planar -CO-NH- amide bond with partial double-bond character (restricted rotation around the C-N axis).
Primary structure: the exact linear sequence of amino acids - one residue swap can cause sickle-cell anaemia (Glu → Val at position 6 in haemoglobin's beta chain).
Secondary structure: local folding patterns. Alpha-helix is a right-handed coil (3.6 residues/turn) held by intra-chain H-bonds from -N-H of residue i to -C=O of residue i+4 (keratin, myoglobin). Beta-pleated sheet is stabilised by inter-chain H-bonds between adjacent strands (silk fibroin).
Tertiary structure: the overall 3-D fold of a single chain, stabilised by disulphide bridges, salt bridges, H-bonds, and van der Waals (myoglobin, lysozyme).
Quaternary structure: assembly of two or more polypeptide chains. Haemoglobin is the canonical example: 2 alpha + 2 beta subunits, each holding a heme group with iron, total M ~64,500 u.
Denaturation: heat, extreme pH, urea, organic solvents, or heavy metal salts disrupt 2°, 3° and 4° but leave 1° (peptide bonds) intact. Boiled egg-white is the classic example - the chains are still polypeptide-linked but no longer folded.
Fibrous vs globular proteins: fibrous (keratin in hair, collagen in connective tissue, fibroin in silk) are linear, water-insoluble, and structural; globular (insulin, albumins, enzymes, haemoglobin) are spherical, water-soluble, and functional. Insulin is the textbook protein hormone - 51 amino acids, two chains held by disulphide bridges, lowers blood glucose.
Enzymes, Vitamins and Nucleic Acids - Sections 10.3 to 10.5 Solutions
Six exercise solutions cover enzymes (10.3), vitamins (10.4), and nucleic acids (10.5). Each block contributes one CBSE 2- or 3-mark slot every year, and the vitamin-deficiency and DNA vs RNA blocks together account for the highest NEET density on the chapter.
Enzymes: globular proteins ending in "-ase" that catalyse biological reactions with extreme substrate specificity (lock-and-key / induced-fit). They lower activation energy without being consumed. NCERT records the sucrose hydrolysis Ea drop: 6.22 kJ/mol (H+ catalysis) → 2.15 kJ/mol (sucrase) - roughly a one-third drop. Optimum pH ~7.4 and temperature ~37 degrees C in mammals; heat or extreme pH causes denaturation.
Vitamins: organic micronutrients required in small amounts. Fat-soluble (ADEK) are A, D, E, K - stored in liver and adipose; water-soluble are B-complex and C - excreted in urine, must be supplied regularly (exception: B12 is stored). Deficiency pairs CBSE / NEET repeatedly tests: A (night blindness / xerophthalmia), B1 thiamine (beri-beri), B2 riboflavin (cheilosis), B6 pyridoxine (anaemia, convulsions), B12 cobalamin (pernicious anaemia), C ascorbic acid (scurvy, bleeding gums), D (rickets in children, osteomalacia in adults), E (sterility, muscular weakness), K (poor blood clotting).
Nucleoside vs nucleotide: a nucleoside is a nitrogen base joined to a pentose sugar (base + sugar, N-glycosidic at C1'); a nucleotide is a nucleoside plus a phosphate group (base + sugar + phosphate, ester at C5'). Only nucleotides polymerise to nucleic acids; the linkage is the 5' to 3' phosphodiester bond.
Purines and pyrimidines: the two ring-class families of nitrogen bases. Purines (two fused rings) = Adenine, Guanine; Pyrimidines (single ring) = Cytosine, Thymine, Uracil. Mnemonic "PURe As Gold" (PURines = A, G); thymine is found only in DNA, uracil only in RNA, cytosine in both.
DNA structure - Watson-Crick double helix: two antiparallel strands (one running 5' to 3', the other 3' to 5') wound into a right-handed helix, held by base pairs A=T (2 H-bonds) and G≡C (3 H-bonds). Chargaff's rule: in any DNA, A = T and G = C. The sugar-phosphate backbone is on the outside; the bases project inward.
DNA vs RNA difference table: Sugar - DNA uses 2'-deoxyribose (no -OH at C2'), RNA uses ribose (-OH at C2'); Bases - DNA has A, G, C, T, RNA has A, G, C, U (uracil replaces thymine); Strand - DNA is a double helix, RNA is single-stranded (folds back in tRNA and rRNA); Function - DNA stores hereditary information and self-replicates, mRNA carries the genetic message, tRNA delivers amino acids, rRNA forms the ribosome.
Hormones: chemical messengers from endocrine glands acting at a distance. The 2026-27 NCERT trims the detailed hormone classification but retains the three chemical classes - steroid (estrogens, testosterone), polypeptide / protein (insulin, glucagon), and amino-acid-derived (thyroxine, epinephrine). Insulin is the protein-hormone benchmark (51 AA, two chains); thyroxine is the iodinated tyrosine derivative whose deficiency causes goitre.
Biomolecules Top Differentiation Pairs (Quick-Recall Block)
The pairs below are the eight highest-frequency comparison questions in this chapter across the last six CBSE papers. The full discussion of each pair lives in the Notes page; here is the at-a-glance table that mirrors what the solutions PDF expands into a two-column answer.
Pair
The one-line distinguishing fact
Marks weight
Starch vs Cellulose
alpha-1,4 glycosidic (starch) vs beta-1,4 glycosidic (cellulose) linkage
2-3 marks
DNA vs RNA
deoxyribose + thymine + double helix (DNA) vs ribose + uracil + single strand (RNA)
2-3 marks
Alpha-helix vs Beta-pleated sheet
intra-strand H-bond (helix) vs inter-strand H-bond (sheet)
2 marks
Essential vs Non-essential amino acids
cannot be synthesised by the body (essential) vs synthesised (non-essential)
1-2 marks
Glucose vs Fructose
aldohexose with -CHO (glucose) vs ketohexose with C=O at C2 (fructose)
2 marks
Globular vs Fibrous protein
spherical, water-soluble (globular, e.g. insulin) vs linear, water-insoluble (fibrous, e.g. keratin)
1-2 marks
Vitamin A vs Vitamin C
fat-soluble, deficiency causes night blindness vs water-soluble, deficiency causes scurvy
1 mark
Reducing vs Non-reducing sugar
free anomeric carbon (e.g. maltose) vs anomeric carbons engaged in linkage (e.g. sucrose)
2 marks
Eight pairs, fewer than 25 marks-bearing facts to memorise. Worth a 60-minute focused session before the board exam.
NCERT Class 12 Chemistry Chapter 10 Exercise-wise Question Map
The Biomolecules chapter in the 2026-27 NCERT has a single main exercise with 24 questions and an intext set of 10 questions placed within the chapter body. The split below shows how Collegedunia has tagged each exercise question by sub-topic so the reader can target the carbohydrate, protein, or nucleic-acid block in isolation.
Disaccharides, polysaccharides, starch and cellulose linkages
Main Exercise Q11-Q15
5
Amino acids, peptide bonds, primary to quaternary protein structure
Main Exercise Q16-Q20
5
Enzymes, mechanism of enzyme action, vitamin classification
Main Exercise Q21-Q24
4
Nucleic acids, DNA double helix, biological functions
Notice the symmetry: each five-question block targets a single biomolecule family. A revision session can therefore focus on one block (proteins, say Q11-Q15) without losing context. The PDF preserves this same ordering so cross-reference is direct.
Biomolecules Class 12 Previous Year Questions Weightage (2021-2026)
The year-wise pattern below shows that Biomolecules has been a steady 3-to-5-mark contributor with one short-answer question per CBSE paper, and a single fact-recall question per NEET paper. JEE Main pulls a question roughly every other shift.
Year
CBSE Board
JEE Main
NEET
2026
Pending
Vitamins classification, 1 Q
Pending (exam rescheduled)
2025
DNA structure, 3 marks; glucose reactions, 2 marks
Disaccharide linkage, 1 Q
Protein structure, 1 Q
2024
Starch vs cellulose, 3 marks
Amino acid classification, 1 Q
Vitamins, 1 Q
2023
Peptide bond + denaturation, 3 marks
-
Nucleic acids, 2 Qs
2022
Glucose open vs cyclic, 2 marks; enzymes, 3 marks
Carbohydrate classification, 1 Q
DNA-RNA difference, 1 Q
2021
Vitamins and deficiency, 2 marks
-
Anomeric carbon, 1 Q
The takeaway: no CBSE paper in the last 6 years has skipped Biomolecules. Plan for at least 3 marks of guaranteed return if the differentiation tables and glucose reactions are memorised.
Common Mistakes Students Make in Biomolecules Answers
Biomolecules looks easy but the most common mark losses come from terminology slips - not concept gaps. The Collegedunia solutions PDF flags each of these inside the relevant answer with a red-margin "Watch Out" tag.
Confusing alpha and beta glycosidic linkages: students write "starch has 1,4 glycosidic linkage" and stop, missing the alpha qualifier that carries 1 of the 3 marks.
Writing "double helix" for RNA: RNA is single-stranded; only DNA is double-helical. A throwaway mistake that costs the full 1-mark MCQ.
Mis-identifying the anomeric carbon: C1 in aldoses (glucose) but C2 in ketoses (fructose). NEET sets this trap regularly.
Calling all polysaccharides "polymers of glucose": only starch, glycogen, and cellulose are; chitin is a polymer of N-acetylglucosamine. The blanket statement loses marks.
Listing the wrong vitamin solubility: Vitamin K is fat-soluble, Vitamin B12 is water-soluble. Mixing them up is a common 1-mark loss.
Forgetting the "non-protein part" of an enzyme: the coenzyme. CBSE 2-mark questions on enzyme structure expect both the apoenzyme and the coenzyme to be named.
Remember: Use the phrase "alpha-D-glucose" in full whenever the answer requires the glucose structure. Dropping the "alpha" or the "D" loses precision marks even when the drawing is correct.
Sample Fully-Solved Question: Why is Sucrose Non-Reducing While Maltose is Reducing?
This 3-mark question has appeared in CBSE 2018, 2022, and 2024. The Collegedunia solutions PDF walks through it as the reference template for every reducing-sugar question in the chapter.
Step 1 (1 mark): Define a reducing sugar. A reducing sugar has a free anomeric carbon (free hemiacetal or hemiketal -OH), which allows the sugar to open into the aldehyde or ketone form and reduce Fehling's or Tollens' reagent.
Step 2 (1 mark): Examine maltose. Maltose is glucose-alpha-1,4-glucose. The first glucose donates its C1 -OH to the linkage, but the second glucose still has a free C1 anomeric -OH. Therefore maltose reduces Fehling's solution and is classified as a reducing disaccharide.
Step 3 (1 mark): Examine sucrose. Sucrose is glucose-alpha-1,beta-2-fructose. Both the C1 anomeric -OH of glucose and the C2 anomeric -OH of fructose are locked into the glycosidic bond. With no free anomeric carbon, sucrose cannot open into its aldehyde or ketone form, so it does not reduce Fehling's solution. Sucrose is non-reducing.
The mark allocation in the table above matches the official CBSE marking scheme for the 2022 and 2024 attempts; following the three-step structure earns the full 3 marks consistently.
Class 12 Chemistry Chapter-wise Marks Distribution (CBSE 2026-27)
The visual below maps the typical CBSE marks distribution across all 10 chapters of the Class 12 Chemistry NCERT, averaged over the last five board papers. Biomolecules sits in the lower band at 4 marks, balanced by the heavyweight Solutions and Coordination Compounds chapters.
All NCERT Solutions for Biomolecules with Step-by-Step Working
Every NCERT textbook question for Class 12 Chemistry Chapter 10 Biomolecules is listed below with its full Solution and Expert Solution hidden inside collapsible tabs. Click Check Solution to reveal the step-by-step working; click Expert Solution for the expanded explanation.
Questions
Q 10.1
What are monosaccharides?
Concept used.Carbohydrates are optically active
polyhydroxy aldehydes or polyhydroxy ketones (or substances that yield
these on hydrolysis). They are classified on the basis of their
behaviour towards hydrolysis: the chemical breaking of a
molecule by addition of water in the presence of an acid or an enzyme.
On hydrolysis, a carbohydrate either splits into smaller
sugar units or does not split at all.
The three families
Carbohydrates are grouped as: monosaccharides (do not hydrolyse
further), oligosaccharides (give 2 to 10 monosaccharide units
on hydrolysis) and polysaccharides (give many monosaccharide
units on hydrolysis).
Define the term. Monosaccharides are those
carbohydrates that cannot be hydrolysed further into
smaller simpler sugar units. They are the simplest carbohydrates
and the fundamental building blocks of all larger
carbohydrates.
Recognise the general molecular formula. The general formula
of a monosaccharide is CnH2nOn where n is usually
3, 4, 5, 6 or 7. Each carbon (except the carbonyl carbon) bears
a hydroxyl (-OH) group; one carbon carries a carbonyl
group (-CHO or >C=O).
Sub-classify. Monosaccharides containing an aldehyde group are
called aldoses; those containing a ketone group are
called ketoses. They are further classified by the
number of carbon atoms: triose (3 C), tetrose (4 C), pentose
(5 C), hexose (6 C), heptose (7 C).
Name common examples.
Aldohexose: glucose, C6H12O6.
Ketohexose: fructose, C6H12O6.
Aldopentose: ribose, C5H10O5.
Aldotriose: glyceraldehyde, C3H6O3.
[See diagram in the PDF version]
Monosaccharides are the simplest carbohydrates that
cannot be hydrolysed further into smaller sugars. About 20
naturally occurring monosaccharides are known. Examples: glucose
(C6H12O6), fructose (C6H12O6) and ribose (C5H10O5).
PS
Pranav Sharma
M.Sc Biochemistry, IIT Bombay
Verified Expert
Definition-first angle. The cleanest way to fix the idea of a
monosaccharide in the mind is to anchor it against the two families
that can be broken down: oligosaccharides and polysaccharides.
A monosaccharide is the end-product of carbohydrate hydrolysis: once
you reach it, water can no longer split it further.
Alternative approach: counting carbons before naming. A neat
mental trick is to read the molecular formula first and the structure
second. Any molecule of the form CnH2nOn where n ∈
3,4,5,6,7 is automatically a monosaccharide of n carbons. So
C3H6O3 is a triose, C5H10O5 a pentose, C6H12O6 a
hexose; whether it is aldo or keto is then decided by which carbon
carries the C=O. This carbon-count-first habit avoids the
common mistake of guessing structure before reading the formula.
Hydrolysis test as a definition. If a carbohydrate X is
boiled with dilute acid (or treated with an enzyme) and the
product is still a carbohydrate of smaller mass, X is not a
monosaccharide. If the same treatment leaves the molecule
unchanged in carbohydrate skeleton, X is a monosaccharide.
General formula CnH2nOn with n = 3 to 7. Plug in
n = 6: C6H12O6 describes glucose, fructose and
galactose, three different monosaccharides with the same
formula but different structures (structural isomers).
Plug in n = 5: C5H10O5 describes ribose (RNA sugar);
the deoxy form C5H10O4 is 2-deoxyribose (DNA sugar).
Reading the family name: aldo- or keto- fixes
the carbonyl type; -triose, -tetrose, -pentose, -hexose
fixes the carbon count. Numerical check: an aldohexose has 4
chiral carbons (C-2, C-3, C-4, C-5), so 24 = 16 possible
stereoisomers; glucose is just one of them.
State examples by category:
Glucose: aldohexose;
Fructose: ketohexose;
Ribose: aldopentose (the sugar in RNA);
2-Deoxyribose: aldopentose with no -OH at C-2
(the sugar in DNA);
Galactose: aldohexose differing from glucose only at
C-4 (a C-4 epimer).
Concept linkage. Monosaccharides are not isolated objects: the
glucose you eat is the same glucose that builds the starch in
a potato, the cellulose in cotton and the lactose in milk. The
family connection is via the glycosidic linkage, a
C-O-C bond joining two monosaccharides into a larger
carbohydrate. Hold this thread loosely now - it returns in
Q5 and Q8.
Why this matters. Every disaccharide and polysaccharide we
will meet (sucrose, lactose, starch, cellulose, glycogen) is built
from monosaccharide ``Lego bricks'' joined by glycosidic linkages.
Knowing the bricks is the first step to reading the polymer. In NEET
and JEE Main this single line, ``carbohydrates that cannot be
hydrolysed further'', is the most-asked one-mark fact from
biomolecules.
Exam-relevance flag. CBSE has asked the definition of a
monosaccharide directly in 2014, 2017 and 2021 (1 mark each), and
asked for ``examples of an aldopentose and a ketohexose'' as part of a
2-mark question in 2019. State the formula and at least one
named example per category.
A monosaccharide is a carbohydrate that cannot be hydrolysed
into a smaller carbohydrate. Formula CnH2nOn (n = 3–7).
Examples: glucose, fructose, ribose.
Q 10.2
What are reducing sugars?
Concept used. A reducing sugar is any carbohydrate
that can reduce a mild oxidising agent. The chemistry behind
the name is simple: the sugar contains a free aldehyde
(-CHO) group, or a free ketone (>C=O) that can tautomerise
to an aldehyde, and this group gets oxidised to a carboxylic acid
while it reduces metal ions like Cu2+ or Ag+ to
Cu+ or Ag0.
Two classic tests
Fehling's test: blue Cu2+ in alkaline tartrate solution
→ brick-red Cu2O precipitate. Tollens' test:
ammoniacal AgNO3→ silver mirror on the inside of the
test tube. A positive result with either reagent confirms a reducing
sugar.
Identify the chemical feature. The functional group that does
the reducing is a free anomeric hydroxyl (which exists in
equilibrium with the open-chain -CHO). In a free
monosaccharide, this -OH is always present at C-1
(or C-2 of fructose), so all free monosaccharides are reducing.
Apply to each class.
All monosaccharides (glucose, fructose, ribose,
galactose) are reducing sugars, because their anomeric
-OH is always free.
Disaccharides are reducing only if at least one
of the two anomeric -OH groups is free. Maltose
and lactose are reducing; sucrose is not (both
anomeric carbons are tied up in the glycosidic bond).
Polysaccharides are essentially non-reducing
because the very few free anomeric ends are
negligible compared to the size of the molecule.
State the redox equation in symbols. With Fehling's reagent:
R-CHO + 2 Cu2+ + 5 OH- -> R-COO- + Cu2O v + 3 H2O.
The red precipitate of Cu2O is the visible sign of a
reducing sugar.
Reducing sugars are carbohydrates that reduce Fehling's
solution to red Cu2O or Tollens' reagent to silver mirror, by
virtue of a free aldehyde / ketone (anomeric -OH) group. All
monosaccharides and most disaccharides (except sucrose) are
reducing sugars.
AI
Aanya Iyer
Ph.D Organic Chemistry, IISc Bangalore
Verified Expert
Structural angle. Think of a sugar's ``reducing power'' as a
question about its anomeric carbon: is it free or is it engaged?
Alternative approach: a flow-chart in three questions. (i) Is
the sugar a free monosaccharide? If yes, it is reducing. (ii) If it is
a disaccharide, ask: are BOTH anomeric centres tied up in the
glycosidic bond? If yes, non-reducing (sucrose, trehalose). If only
one is tied up, reducing (maltose, lactose, cellobiose). (iii) If it
is a polysaccharide, the one or two free ends are negligible compared
to the molecular mass, so the polysaccharide is operationally
non-reducing.
Locate the anomeric carbon. In an aldose, it is C-1 (the one
with the -CHO in the open chain or with the
hemiacetal -OH in the ring). In a ketose like fructose,
it is C-2. The anomeric carbon is the only one that carries
two oxygens after cyclisation - a ring-O and a
hemiacetal -OH.
``Free'' anomeric centre ⇒ sugar can open into the
chain form ⇒ free aldehyde ⇒ reduces
Cu(II)/Ag(I). ``Locked'' anomeric centre (engaged in a
glycosidic bond) ⇒ no open chain ⇒ no
reduction. The hemiacetal open-chain
aldehyde equilibrium is what supplies the trace of -CHO
that the test reagent oxidises.
Quick verdict table.
Glucose, fructose, galactose, mannose: free ⇒
reducing. (Fructose, though a ketose, tautomerises in
alkaline Fehling's medium to an aldose via the
Lobry-de-Bruyn-van-Ekenstein rearrangement, hence it
tests positive.)
Maltose, lactose: only ONE anomeric centre locked,
the other free ⇒ reducing.
Sucrose: BOTH anomeric centres locked ⇒
non-reducing. The glycosidic bond between C-1 of
glucose and C-2 of fructose is a head-to-head linkage
that uses up both reducing groups.
Concept linkage to amino acids and proteins. ``Reducing
groups'' in biomolecules is a recurring theme: a free
-CHO in a sugar, a free -NH2 in an amino acid, a
free 5'-end in a nucleic acid. Each ``free'' end is a
chemical handle. As soon as biology wants to make a polymer,
it spends those free ends in covalent linkages.
Why this matters. The reducing/non-reducing distinction is
the first chemical fingerprint of an unknown sugar in the lab and the
basis of Benedict's test for glucose in urine (a common diabetes
screen). It is also a standard 2-mark CBSE prompt: ``Why is sucrose
non-reducing whereas maltose is reducing?''
Exam-relevance flag. The most common trap is to mark fructose
as non-reducing because it is a ketone - wrong. Fructose IS reducing
because alkaline Fehling's medium tautomerises it. Equally, do not
mark starch as ``reducing because it has glucose units'' - wrong, its
many anomeric carbons are all locked in glycosidic bonds.
Reducing sugars contain a free aldehyde or hemiacetal that
gets oxidised by Fehling's or Tollens' reagent; all monosaccharides
and disaccharides except sucrose are reducing.
Q 10.3
Write two main functions of carbohydrates in plants.
Concept used. Carbohydrates serve plants in two broad ways:
as energy stores and as structural materials. Each
role is played by a different polysaccharide built from glucose
monomers.
Function 1: Storage of chemical energy. Starch is the main carbohydrate used by plants to
store the chemical energy captured in photosynthesis. Starch
is deposited as granules in seeds, tubers and roots. When the
plant needs energy, enzymes hydrolyse starch to glucose, which
is oxidised in respiration to release ATP.
Function 2: Structural support of cell walls. Cellulose is the principal structural polysaccharide
of plants. It is a linear polymer of β-D-glucose units
joined by C1→C4 glycosidic linkages. The straight chains
align side-by-side and hydrogen-bond into rigid microfibrils
that give the cell wall its tensile strength. Wood, cotton and
flax are largely cellulose.
[See diagram in the PDF version]
Two main functions of carbohydrates in plants: (i)
storage of food energy as starch, and (ii) structural
support of cell walls as cellulose.
AV
Aditya Verma
M.Sc Biochemistry, IIT Kanpur
Verified Expert
Picture-first angle. Two polymers, same monomer, two
completely different jobs. The difference is one stereochemical detail
at C-1.
Alternative approach: think of the plant as a bank. Sugars
made by photosynthesis are like cash flowing in. The plant has to
park some of that cash in the vault (energy reserve → starch
granules) and use some of it to build the walls of the bank (cell-wall
material → cellulose microfibrils). One polymer is liquid (easy to
hydrolyse back to glucose), the other is fixed (hard to hydrolyse).
This ``bank-vs-bricks'' analogy makes the dual function memorable.
Energy stores need to release glucose on demand. Starch is
α-D-glucose polymerised through α-1,4 (and
α-1,6 in amylopectin) glycosidic bonds. The α
geometry produces a helical, easily-hydrolysable chain that
amylase enzymes can quickly digest. Starch granules in the
endosperm of wheat and rice are exactly this kind of mobile
energy reserve.
Structural roles need a rigid, water-resistant fibre. Cellulose
is β-D-glucose polymerised through β-1,4 links. The
β geometry forces each successive glucose to flip 180∘,
producing a straight ribbon. Hundreds of ribbons hydrogen-bond
into microfibrils that are insoluble in water and resistant to
attack by most digestive enzymes. Cotton fibre is more than
90% pure cellulose; wood is about 50%.
Concept linkage to proteins and nucleic acids. The same
``storage vs structure'' duality reappears later: globular
proteins (storage of catalytic identity) vs fibrous proteins
(collagen, structural); DNA (storage of information) vs the
ribosome and microtubules (structural scaffolding). The
``two-jobs'' design pattern is universal in biology.
Why this matters. Cows can graze grass because their gut
bacteria produce cellulase; humans cannot, so cellulose passes through
us as dietary fibre. The same molecule (glucose), assembled with two
different stereochemistries, gives two utterly different biological
roles. This single fact powers most of the world's textile industry
(cotton, linen, viscose) and most of the world's food calories (rice,
wheat, maize starch).
Exam-relevance flag. CBSE has asked ``State two functions of
carbohydrates in plants'' as a 2-mark VSA in 2015, 2018 and 2022. The
expected answer is the simple pair ``energy storage (starch)'' +
``structural support (cellulose)''. One extra mark is sometimes given
for naming a specific tissue (endosperm/cell wall).
In plants, carbohydrates (i) store chemical energy
(starch) and (ii) build the cell wall (cellulose).
Q 10.4
Classify the following into monosaccharides and disaccharides:
Ribose, 2-deoxyribose, maltose, galactose, fructose and lactose.
Concept used. Apply the hydrolysis test from Q1. A
monosaccharide cannot be hydrolysed into a smaller sugar; a
disaccharide hydrolyses into exactly two monosaccharide
units.
Go through each name and recall whether it hydrolyses.
Ribose: aldopentose (C5H10O5); does
not hydrolyse. Monosaccharide.
2-Deoxyribose: aldopentose with no -OH
at C-2; does not hydrolyse. Monosaccharide.
Maltose: hydrolyses to two glucose units.
Disaccharide.
Galactose: aldohexose (C6H12O6); does
not hydrolyse. Monosaccharide.
Fructose: ketohexose (C6H12O6); does
not hydrolyse. Monosaccharide.
Lactose: hydrolyses to glucose + galactose.
Disaccharide.
Pattern-spotting angle. A useful mnemonic: most disaccharides
end in ``-ose'' and contain the syllable indicating a pair (sucr-,
malt-, lact-). All four other names here are simple sugar names you
have seen separately in metabolism.
Alternative approach: molecular-formula sieve. Each
monosaccharide on the list obeys CnH2nOn (ribose
C5H10O5, fructose C6H12O6, etc.), while each
disaccharide on the list obeys C12H22O11 (maltose,
lactose). Counting atoms in the formula immediately classifies the
sugar: total carbon ≤ 7⇒ monosaccharide; carbon =
12 with one water lost ⇒ disaccharide.
Carbon count check. Ribose and 2-deoxyribose are 5-carbon
pentoses (C5H10O5 and C5H10O4 respectively).
Galactose and fructose are 6-carbon hexoses (C6H12O6).
All four are single-ring sugars: monosaccharides.
Hydrolysis check. Maltose is barley sugar
(C12H22O11); hydrolysis gives 2 glucose. Lactose is
milk sugar (C12H22O11); hydrolysis gives glucose +
galactose. Both are double-ring sugars: disaccharides.
Stereochemical note. Galactose and glucose are
C-4 epimers- they differ only at C-4. Fructose is a
structural isomer of glucose, differing in functional
group (ketone vs aldehyde) not in stereochemistry. Knowing
these relations helps you read more advanced Exemplar
questions.
Final grouping in two lists exactly as in the boxed answer.
Why this matters. Recognising the family of a sugar at sight
is the foundation for understanding why milk gives babies energy
(lactose → glucose + galactose) and why bread tastes sweeter as
you chew (amylase breaks starch to maltose, then to glucose). It also
prepares the ground for Q5, Q6 and Q7, where we look at the
glycosidic bond that joins these monosaccharides into the actual
disaccharides on the list.
Concept linkage. Of the four monosaccharides here, ribose and
2-deoxyribose reappear as the sugar backbones of RNA and DNA (Q21,
Q24); galactose is one half of lactose; fructose is one half of
sucrose. So today's classification is tomorrow's biopolymer chemistry.
What do you understand by the term glycosidic linkage?
Concept used. A glycosidic linkage is the covalent
C-O-C bond that joins two monosaccharide units in a di- or
poly-saccharide. It is formed by a condensation reaction in which the
hemiacetal -OH at the anomeric carbon of one sugar reacts with
an -OH of a second sugar, eliminating one molecule of water.
Anomeric carbon, hemiacetal
The anomeric carbon of a cyclic sugar is the carbon that was
the carbonyl carbon in the open chain (C-1 in aldoses, C-2 in
ketoses). It carries the hemiacetal-OH that condenses
with another sugar to form a glycosidic bond.
General reaction (with loss of H2O):
Sugar1-OH + HO-Sugar2 -> Sugar1-O-Sugar2.
The new C-O-C bond is the glycosidic linkage.
In sucrose, C-1 of α-D-glucose is linked to C-2 of
β-D-fructose: this is an α-1,2-glycosidic linkage.
In maltose, C-1 of one α-D-glucose is linked to C-4 of
a second α-D-glucose: an α-1,4-glycosidic linkage.
In lactose, C-1 of β-D-galactose is linked to C-4 of
β-D-glucose: a β-1,4-glycosidic linkage.
[See diagram in the PDF version]
A glycosidic linkage is the C-O-C bond formed when
the hemiacetal -OH of one sugar condenses with an -OH of
another sugar, with elimination of H2O. It is the bond that
joins monosaccharide units in di- and poly-saccharides.
KJ
Karan Joshi
M.Sc Chemistry, IIT Madras
Verified Expert
Reaction-mechanism angle. A glycosidic bond is just an acetal
formed from a hemiacetal: classical organic chemistry applied to
sugars.
Alternative approach: Fischer vs Haworth notation. A Fischer
projection draws the open chain vertically with -CHO at the
top; the glycosidic bond cannot be shown easily because the chain has
to close into a ring first. The Haworth projection draws the cyclic
form as a flat hexagon (pyranose) or pentagon (furanose) with the
glycosidic -O- shown as a clean bond between two ring carbons.
Whenever a question mentions a glycosidic bond, switch to Haworth -
the structure jumps off the page.
Open-chain glucose has -CHO at C-1. When it cyclises,
the C-5 -OH attacks the -CHO carbon, generating a
hemiacetal: a carbon bearing -OH and -OR
on the same atom. This is the same hemiacetal step you learned
for aldehyde + alcohol → hemiacetal in the carbonyl
chemistry of Class 12 Unit 8.
The new -OH at C-1 (the anomeric hydroxyl) is reactive.
A second alcohol R'-OH can displace water from it to
give the corresponding acetal: a carbon bearing two
-OR groups. This C-O-R' is the glycosidic
linkage. The α or β label tells you which face of
the ring the new -OR projects from.
Hence every disaccharide is, mechanistically, the acetal of a
sugar with another sugar acting as the alcohol. The general
notation α-1,4 says: α-anomer of the first sugar
+ its C-1 + bonded through O + to C-4 of the second sugar.
Numerical / structural assignment of D vs L. In a Haworth
projection drawn with C-1 at the right and the ring oxygen at
the top right, the -CH2OH at C-6 points up for
D-sugars and down for L-sugars. In the Fischer
projection, look at the highest-numbered chiral carbon
(C-5 in a hexose): -OH on the right ⇒
D-sugar; on the left ⇒ L-sugar. All naturally
occurring monosaccharides in food are D-sugars.
Why this matters. Acetals are stable to base but cleaved by
acid or by specific enzymes (glycosidases). That is exactly why
sugars survive in plant cells (largely neutral pH) and yet are
digested in the small intestine, where amylase and maltase quickly
hydrolyse the glycosidic bond back to monosaccharides. The same
acetal stability is also why processed sugar (sucrose) keeps for years
on the shelf.
Exam-relevance flag. CBSE often pairs ``Define glycosidic
linkage'' with ``state the type of glycosidic bond in sucrose /
maltose / lactose / cellulose''. Memorise the table: sucrose
α-1,β-2; maltose α-1,4; lactose β-1,4;
cellulose β-1,4; starch α-1,4 with α-1,6 branches;
glycogen α-1,4 + α-1,6.
Glycosidic linkage = the C-O-C (acetal) bond joining
two monosaccharide units, formed by condensation between the anomeric
-OH of one sugar and an -OH of the next.
Q 10.6
What is glycogen? How is it different from starch?
Concept used.Glycogen is the storage
polysaccharide of animals: the polymeric form in which the human and
animal body stores glucose. It is a highly branched polymer of
α-D-glucose linked by α-1,4 glycosidic bonds in the main
chains and α-1,6 bonds at the branch points.
Where it is stored. Glycogen is stored mainly in the
liver (large reserve, regulates blood glucose) and in
skeletal muscle (used directly for muscle contraction).
It is often called animal starch because of its role.
Compare with starch. Starch, the storage carbohydrate
of plants, is a mixture of two polysaccharides:
amylose (linear, α-1,4 linked, ∼15–20%)
and amylopectin (branched, α-1,4 with α-1,6
branch points, ∼80–85%).
Therefore the structural difference is the degree of
branching: glycogen is more highly branched than
amylopectin, with branch points roughly every 8–12 glucose
residues (vs every 24–30 in amylopectin).
[See diagram in the PDF version]
Glycogen is the animal storage polysaccharide of
α-D-glucose, stored in liver and muscle. It is more highly
branched than starch and contains only one type of polymer, while
starch is a mixture of mostly-linear amylose and lightly-branched
amylopectin.
AB
Ananya Banerjee
Ph.D Molecular Biology, NCBS Bangalore
Verified Expert
Comparison angle. Glycogen and starch are first cousins: same
monomer (glucose), same family of bonds (α-1,4 and α-1,6),
different geometries.
Alternative approach: count the chain ends. Each branch is a
new chain end. The number of chain ends per molecule sets the
maximum rate at which phosphorylase enzymes can release glucose
phosphate. Glycogen, with the densest branching (every 8–12 residues),
has the most ends per gram and so releases glucose fastest. Starch
(amylopectin branched every 24–30 residues; amylose unbranched) is
slower. Plants do not mind: their metabolic clock is days, not seconds.
Glycogen → branched at every 8–12 residues; appears as a
bush-shaped molecule under the electron microscope. Stored in
cytosolic granules in liver and muscle cells. Liver glycogen
regulates blood glucose between meals; muscle glycogen powers
sprinting and weight-lifting.
Amylose component of starch → unbranched, helical coil of
α-1,4-linked glucose. Gives the characteristic deep-blue
iodine-starch complex (iodine sits inside the helix). About
15–20% of typical plant starch.
Amylopectin component of starch → branched but less than
glycogen. Branching every 24–30 residues. About 80–85% of
typical plant starch.
Functional consequence: glycogen's many branches give animals
rapid access to glucose; starch's fewer branches suit plants'
slower energy demands.
Concept linkage to the chapter map. The four polysaccharides
you see in this chapter - amylose, amylopectin, cellulose,
glycogen - are all polymers of D-glucose. The only variables
are (i) anomer (α vs β) and (ii) branching
pattern. With this single insight all four polysaccharides
compress into a single table.
Why this matters. The same chemistry can be tuned by
branching density to give two very different physiological storage
strategies. This is one of the cleanest examples in biochemistry of
``structure dictates rate''.
Exam-relevance flag. ``Why is glycogen more branched than
starch?'' is a recurring 3-mark CBSE question (asked 2016, 2020). The
expected line is the one above: ``Animals need rapid glucose release,
so more branches ⇒ more chain ends ⇒ faster
mobilisation.'' Memorise the two numbers 8--12 vs
24--30 to score the data mark.
Glycogen is the animal-body equivalent of starch, but more
highly branched. Glycogen contains a single, heavily branched polymer
of α-D-glucose; starch is a mixture of mostly-linear amylose
and moderately branched amylopectin.
Q 10.7
What are the hydrolysis products of
(i) sucrose and (ii) lactose?
Concept used. A disaccharide is the condensation product of
two monosaccharides; on hydrolysis (acid or enzyme
catalysed), the glycosidic bond is cleaved by addition of water and
the two original monosaccharides are recovered.
Disaccharide + H2O H+ Monosaccharide1 + Monosaccharide2.
Sucrose (C12H22O11), common cane or table sugar, is
joined through an α-1,β-2 glycosidic bond. On
hydrolysis with dilute mineral acid or the enzyme invertase:
C12H22O11 + H2O ->[H+/invertase]
C6H12O6 + C6H12O6
i.e. D-(+)-glucose and D-(-)-fructose in
equimolar amounts. This hydrolysis is called the
inversion of sucrose because the optical rotation
changes from +66.5∘ (sucrose, dextrorotatory) to
-19.9∘ (the mixture, levorotatory, because the strongly
levorotatory fructose dominates over the dextrorotatory
glucose).
Lactose (C12H22O11), the natural sugar of mammalian
milk, contains a β-1,4 glycosidic bond. On hydrolysis
with dilute acid or the intestinal enzyme lactase:
C12H22O11 + H2O ->[H+/lactase]
C6H12O6 + C6H12O6
i.e. β-D-galactose and β-D-glucose.
[See diagram in the PDF version]
(i) Sucrose →D-glucose + D-fructose.
(ii) Lactose →D-galactose + D-glucose.
RM
Rohit Mehta
M.Sc Biochemistry, IIT Madras
Verified Expert
Quick reading. Two disaccharides, two hydrolyses, four
monosaccharides in total. Glucose appears in both products.
Alternative approach: acid or enzyme. Both cleavages can be
driven by either dilute mineral acid (general, slow, no specificity)
or by a specific enzyme: invertase (also called sucrase) for
sucrose; lactase for lactose; maltase for maltose. The
enzyme route is fast and specific (one enzyme per substrate) and is
the route used in your small intestine.
Sucrose: α-D-glucopyranosyl-β-D-fructofuranoside.
Acidic hydrolysis cleaves the unique α,β-1,2
glycosidic bond to give glucose + fructose. The reaction is
sometimes called invertase hydrolysis; the product
mixture (equal moles of glucose and fructose) is invert
sugar (Honey contains a lot of invert sugar).
Lactose: β-D-galactopyranosyl-(1→4)-D-glucose. Acid
or the enzyme lactase cleaves the β-1,4 bond to give
galactose + glucose. People with lactose intolerance lack the
enzyme lactase, so undigested lactose passes to the colon and
causes discomfort. Genetic ``lactase persistence'' into
adulthood is concentrated in north-European and north-Indian
populations.
Concept linkage to Q5. Both hydrolyses are the chemical
reverse of the glycosidic-linkage formation discussed
in Q5. Q5: condensation, loss of H2O; Q7: hydrolysis,
addition of H2O. Same bond, two directions.
Why this matters. Hydrolysis turns a dietary disaccharide
into absorbable monosaccharides. Without this single chemical step
sucrose and lactose could not nourish us. The same hydrolysis
chemistry powers fermentation in industry: sucrose → glucose +
fructose → ethanol + CO2 (in yeast).
Exam-relevance flag. CBSE asks ``Write the hydrolysis
products of sucrose / lactose / maltose'' as a 2-mark VSA almost
every year. The answer is two reagents + two products + (optional)
the enzyme name. Add the inversion-of-sucrose line for an extra mark.
What is the basic structural difference between starch and cellulose?
Concept used. Both starch and cellulose are polysaccharides
of D-glucose, yet they differ in one stereochemical detail at C-1 of
each monomer and one consequence in chain shape. That detail is the
α vs βanomeric configuration.
Starch is built from α-D-glucose units. In each unit
the -OH at C-1 points downward relative to the
ring plane (α-anomer). Adjacent residues are
joined by α-1,4 glycosidic linkages; amylopectin
contains α-1,6 branch points. The α geometry
produces a helical (coiled) chain.
Cellulose is built from β-D-glucose units. In each unit
the -OH at C-1 points upward (β-
anomer). Adjacent residues are joined exclusively by β-
1,4 glycosidic linkages. The β geometry forces each
successive glucose to flip 180∘, producing a long,
straight, ribbon-like chain.
Macroscopic consequence. Helical α-glucan chains pack
loosely and trap iodine to give the deep-blue starch-iodine
colour; straight β-glucan chains hydrogen-bond
side-by-side into rigid microfibrils that build cell walls
and cannot be digested by humans.
[See diagram in the PDF version]
Starch consists of α-D-glucose units linked by
α-1,4 (and α-1,6 branch) glycosidic bonds and forms a
coiled chain; cellulose consists of β-D-glucose units linked
exclusively by β-1,4 glycosidic bonds and forms a straight,
fibrous chain.
VN
Vivaan Nair
Ph.D Organic Chemistry, IISc Bangalore
Verified Expert
Structural angle. The whole difference rides on the chirality
at C-1 of each monomer. Two letters (α, β), two completely
different biological materials.
Alternative approach: Haworth projection comparison. Draw
two glucose hexagons. For α-glucose the C-1 -OH points
down (below the ring plane); for β-glucose it points
up. In the polymer, the α linker holds successive rings
on the same face, so the chain curls into a helix. The β linker
forces every second ring to flip, so the chain straightens into a
ribbon. Sketching two adjacent hexagons in each linkage type makes the
geometric difference unforgettable.
Same monomer: C6H12O6 (D-glucose).
Two anomers at C-1: α (-OH down) and β
(-OH up). Both exist in equilibrium with the open chain
in solution (mutarotation), but once the monomer enters
a glycosidic bond, its anomeric configuration is locked. This
is the same mutarotation phenomenon discussed in Q10 below.
In starch every glycosidic bond is α; in cellulose
every bond is β. The cumulative effect over thousands of
residues converts a flexible coil (starch) into a rigid rod
(cellulose). The ribbon-like cellulose chains then
hydrogen-bond side-by-side into microfibrils that build
the plant cell wall.
Enzymatic consequence: amylases that recognise α-1,4 do
not bind β-1,4 (and vice versa). Humans secrete amylase
but not cellulase, so we digest starch but not cellulose. Cows,
sheep and termites host gut bacteria that secrete cellulase
and so derive nutrition from grass and wood.
Concept linkage. The α vs β choice is exactly the
same chemical handle that distinguishes maltose (α-1,4)
from cellobiose (β-1,4), and is one of the few places in
the chapter where pure stereochemistry has a macroscopic
biological consequence.
Why this matters. The simplest possible change in stereochemistry
- flipping one -OH from down to up - converts the body's main
fuel into one of the strongest natural fibres. It is a clean reminder
that biology cares about three-dimensional shape, not just composition.
Exam-relevance flag. ``State the basic structural difference
between starch and cellulose'' is a stand-alone 2-mark CBSE question
(asked 2014, 2017, 2023). Two crisp lines -α-1,4 vs β-1,4
+ helical vs linear - get full marks.
Starch = α-1,4 (and α-1,6) linked
α-D-glucose, helical and digestible; cellulose = β-1,4
linked β-D-glucose, linear and indigestible (to humans).
Q 10.9
What happens when D-glucose is treated with the following reagents?
(i) HI (ii) Bromine water (iii) HNO3.
Concept used. The reactions of glucose tell us about its
functional groups. Open-chain D-glucose,
CH2OH(CHOH)4CHO, contains five -OH groups and one
-CHO group; the cyclic form (pyranose) contains a hemiacetal.
Different reagents probe different features.
(i) With prolonged heating with excess HI. HI is a strong reducing agent that cleaves C-O
bonds and replaces -OH groups with -H. Heating
glucose with concentrated HI (red phosphorus, Δ)
removes all five -OH groups and reduces the -CHO
as well, giving a straight-chain alkane with the same carbon
skeleton:
CH2OH-(CHOH)4-CHO ->[HI, P, Δ] CH3-(CH2)4-CH3
i.e. n-hexane. This product confirms that glucose has
a straight chain of six carbon atoms.
(ii) With bromine water.
Bromine water is a mild oxidising agent that oxidises an
aldehyde to the corresponding carboxylic acid (but does not
oxidise primary or secondary alcohols). With glucose:
CH2OH-(CHOH)4-CHO ->[Br2/H2O]
CH2OH-(CHOH)4-COOH
The product is D-gluconic acid, a monocarboxylic acid.
This proves the presence of an aldehyde group in glucose.
(iii) With nitric acid (concentrated, on heating).
HNO3 is a stronger oxidising agent. It oxidises both the
-CHO at C-1 and the primary -CH2OH at C-6 to
-COOH groups, but leaves the secondary -OH groups
intact:
CH2OH-(CHOH)4-CHO conc. HNO3, Δ HOOC-(CHOH)4-COOH
The product is the dicarboxylic acid D-saccharic acid
(also called D-glucaric acid). This shows that glucose has a
primary alcoholic (-CH2OH) group along with an
aldehyde.
[See diagram in the PDF version]
(i) HI →n-hexane; (ii) Bromine water →gluconic acid; (iii) HNO3 →saccharic acid
(D-glucaric acid).
YK
Yash Kapoor
M.Sc Chemistry, IIT Kanpur
Verified Expert
Picture-first angle. Each reagent is a chemical ``stain''
that lights up one feature of glucose's open chain.
Alternative approach: read the carbon count of each product.n-Hexane has 6 carbons in a straight chain → glucose has 6 carbons
in a straight chain. Gluconic acid has 6 carbons and one -COOH→ glucose has one -CHO at the end. Saccharic acid has 6
carbons and two -COOH groups → glucose has -CHO at
one end and -CH2OH at the other end. Three products, three
structural facts.
HI is the most aggressive: every oxygen leaves the molecule.
What is left is the bare carbon skeleton, which proves
straight chain of six carbons (the carbons cannot
rearrange under HI conditions). Mechanism: HI reduces each
C-OH via C-OH → C-I → C-H (the iodide is
then displaced by HI acting as a hydride source).
Bromine water is selective: only the aldehyde is oxidised to
-COOH. The fact that a monocarboxylic acid (gluconic
acid) forms proves that there is exactly one aldehyde group.
Bromine water does not touch the primary or secondary
-OH groups under these conditions.
HNO3 is stronger still: it gets both the aldehyde and the
primary alcohol. The fact that a dicarboxylic acid (saccharic
acid) forms proves that there is also a primary -OH
somewhere - at the opposite end of the chain (C-6), since
secondary alcohols are not oxidised by HNO3 at the same
temperature.
Concept linkage. These three reactions together prove the
open-chain structure CH2OH-(CHOH)4-CHO. But Q10 will
immediately show that this open chain is not the whole story
and that a cyclic hemiacetal is also required. Q9 + Q10
together teach you the full ``story of D-glucose''.
Why this matters. These three classical reactions are the
historical evidence behind the open-chain structure
CH2OH-(CHOH)4-CHO for D-glucose. They are textbook examples of
how organic chemists deduce the skeleton of an unknown by sequential
``probe'' reactions.
Exam-relevance flag. This is a 3-mark CBSE staple. Marks
break-up: 1 mark per product (named correctly with formula). The
diagram of glucose → three arrows → three products is worth a
bonus mark when neatly drawn.
HI →n-hexane; bromine water → gluconic acid;
HNO3 → saccharic acid.
Q 10.10
Enumerate the reactions of D-glucose which cannot be
explained by its open chain structure.
Concept used. The open-chain (Fischer) structure of D-glucose
CH2OH-(CHOH)4-CHO does not account for every experimental
observation. Whenever a property points to a free aldehyde and another
property denies it, we need a second, cyclic hemiacetal
structure to reconcile both.
Glucose does not give the classical 2,4-dinitrophenylhydrazone
with 2,4-DNP, nor does it form a bisulphite addition product
with NaHSO3. Both reactions are characteristic of free
aldehydes; their failure suggests the aldehyde group of
glucose is not freely available.
Glucose does not respond to the Schiff's test for aldehydes
(which gives the magenta colour with rosaniline / fuchsin).
Again, a normal aldehyde would test positive.
Pentaacetate of glucose (obtained by treating glucose with
acetic anhydride) does not react with hydroxylamine
NH2OH. This shows that the -CHO group is no
longer present in the acetate, meaning C-1 is not actually
-CHO but is instead an -OH that gets acetylated.
Six -OAc groups are obtained from glucose, not five -
the extra one comes from the C-1 hemiacetal -OH.
Glucose exists in two crystalline forms with different specific
rotations: α-D-glucose, [α]D = +111∘, and
β-D-glucose, [α]D = +19.2∘. A fresh solution
of either form slowly changes its rotation until both reach an
equilibrium value of +52.7∘. This phenomenon is called
mutarotation and is impossible to explain with a
single open-chain structure. It is explained by the existence
of two cyclic anomers in equilibrium with each other through
the open chain.
[See diagram in the PDF version]
Failures of the open-chain structure: (i) no 2,4-DNP
hydrazone; (ii) no bisulphite addition; (iii) no Schiff's test
colour; (iv) glucose pentaacetate is unreactive to NH2OH; (v)
mutarotation: existence of two crystalline anomers (α and
β) with different specific rotations.
TD
Tara Desai
M.Sc Biochemistry, JNU
Verified Expert
Evidence-first angle. The cyclic structure of glucose was
deduced from these anomalies, not assumed beforehand. Five
clean experiments, one new structure.
Alternative approach: ask ``what would a real aldehyde do?''
For each test, picture what acetaldehyde or benzaldehyde would do:
form a 2,4-DNP, give a bisulphite adduct, turn Schiff reagent pink,
react with NH2OH. Now compare with glucose. Wherever glucose
fails, it is hiding its -CHO inside a ring. The cyclic
hemiacetal answer is just one structural change that explains all
five experimental failures in one stroke.
No 2,4-DNP. A free -CHO would give an orange-yellow
hydrazone with 2,4-dinitrophenylhydrazine. Glucose does not
(or only very slowly through the trace amount of open chain
at equilibrium).
No bisulphite addition. Aldehydes form crystalline
R-CH(OH)-SO3Na with NaHSO3. Glucose does not.
No Schiff's colour. The Schiff reagent gives a magenta dye
with aldehydes. Glucose is silent.
Glucose pentaacetate (5 -OAc on the open chain, or 6
-OAc on the cyclic form - in practice you can isolate
only the cyclic acetate) does not react with NH2OH,
showing C-1 is no longer -CHO.
Mutarotation. Two crystalline anomers, one rotation each, both
drift to the same equilibrium value: the chain is opening and
closing in solution. Numerically, α-D-glucose
([α]D = +111∘) and β-D-glucose
([α]D = +19.2∘) both relax to the equilibrium
+52.7∘ in water; that single specific-rotation triple
is a CBSE favourite.
Concept linkage. The same hemiacetal-acetal story you learned
in Unit 8 (aldehydes + alcohols → hemiacetal → acetal)
is the engine of glucose's cyclic form, of the glycosidic
linkage (Q5), and of every disaccharide and polysaccharide in
the chapter.
Why this matters. The pyranose ring is the foundational
picture for everything that follows in biochemistry: starch,
cellulose, glycogen, nucleic-acid sugars, glycoproteins. All of it
rests on these five anomalies and their cyclic-form explanation.
Exam-relevance flag. CBSE has asked this 5-marker as recently
as 2022. Score full marks by writing exactly 5 anomalies + 1
concluding line about the pyranose ring + a labelled diagram showing
α open chain β.
Open-chain glucose cannot explain: lack of 2,4-DNP /
bisulphite / Schiff colour, formation of glucose pentaacetate inert to
NH2OH, and mutarotation. The cyclic hemiacetal (pyranose) form
resolves all five.
Q 10.11
What are essential and non-essential amino acids? Give two
examples of each type.
Concept used. The human body synthesises proteins from twenty
standard α-amino acids. Ten of these we can make from
other metabolites; the other ten must come from the diet. The dietary
ones are called essential; the others are non-essential.
Essential amino acids are those amino acids that
the human body cannot synthesise (or cannot synthesise
in adequate amounts) and which therefore must be supplied
through food. Their absence from the diet leads to protein
deficiency disorders such as kwashiorkor.
Non-essential amino acids are those amino acids that
the body can synthesise from other amino acids and
metabolic intermediates, so they need not be supplied
ready-made in food.
Essential amino acids must be supplied through diet (the
body cannot make them): examples include valine and
leucine. Non-essential amino acids can be made by the body
itself: examples include glycine and alanine.
IB
Ishita Bhat
M.Sc Biotechnology, AIIMS Delhi
Verified Expert
Definition-first angle. ``Essential'' is a nutritional
adjective, not a chemical one: it tells you about human metabolism,
not about how the amino acid behaves in a peptide.
Alternative approach: how does the question set up the answer?
The question asks for both the definition and two examples of
each type. Write the definitions in parallel form: ``Essential =
cannot be synthesised must come from diet''; ``Non-essential
= can be synthesised need not come from diet''. Parallel
phrasing helps the marker tick both halves. Add two examples per type,
no more (extra examples don't add marks).
All twenty standard α-amino acids are chemically similar:
each has -NH2, -COOH, -H and a side chain
R on the central (α) carbon. The chemical
identity of the amino acid is set by the side chain.
Whether we call one ``essential'' depends on whether human
cells have the enzymes to synthesise its carbon skeleton. We
lack such enzymes for lysine, methionine, tryptophan,
threonine, valine, leucine, isoleucine, phenylalanine,
histidine and (for children) arginine.
Two examples each, as required:
Essential: lysine, leucine.
Non-essential: glycine, alanine.
Numerical note for assignment. ``9 essential'' is the standard
adult count (some textbooks say 10 by including arginine as
conditionally essential for infants). Out of 20 standard amino
acids, 9 essential + 11 non-essential is the safe count for
Class-12 CBSE.
Concept linkage to proteins (Q12) and enzymes (Q17). Every
peptide bond in every protein you eat is hydrolysed in the
stomach back to amino acids; your cells then re-link them into
your own proteins. So a dietary deficiency in any one
essential amino acid limits the synthesis of every protein
that contains it.
Why this matters. A vegetarian diet has to be designed so
that lysine (low in cereals) and methionine (low in pulses)
complement each other, ensuring all essentials are present. This is
the chemical reason why the rice-dal (or roti-dal) combination is the
nutritional backbone of Indian cuisine.
Exam-relevance flag. CBSE has asked this question almost
verbatim in 2015, 2018, 2020 and 2023. The expected answer is exactly
two definitions + two examples each + (optional) a line on dietary
significance. Stick to that template; don't list all ten essentials.
Essential: must come from diet (e.g. lysine, leucine).
Non-essential: synthesised by the body (e.g. glycine, alanine).
Q 10.12
Define the following as related to proteins:
(i) Peptide linkage (ii) Primary structure (iii) Denaturation.
Concept used. Proteins are polymers of α-amino acids
linked by peptide bonds. Their three-dimensional shape is organised
into four hierarchical levels (primary, secondary, tertiary,
quaternary). Heat or chemical assault can destroy higher-order
structure - a process called denaturation.
(i) Peptide linkage. The peptide bond (or
peptide linkage) is the amide bond -CO-NH- formed by a
condensation reaction between the α-carboxyl
(-COOH) group of one amino acid and the α-amino
(-NH2) group of the next amino acid, with loss of one
molecule of water (loss of H2O):
!$H2N-CHR1-COOH + H2N-CHR2-COOH -> H2N-CHR1-CO-NH-CHR2-COOH$.
The product H2N-CHR1-CO-NH-CHR2-COOH is a
dipeptide. Repeating this condensation builds tri-,
tetra-,, polypeptides.
(ii) Primary structure. The primary structure of a
protein is the specific linear sequence of amino acids
joined by peptide bonds, read from the N-terminus
(free -NH2) to the C-terminus (free -COOH). Even
a single change in this sequence may produce a totally
different protein (e.g. one amino-acid change converts normal
haemoglobin into sickle-cell haemoglobin).
(iii) Denaturation. Denaturation is the loss of a
protein's biological activity due to the destruction of its
secondary, tertiary and quaternary structure, while the
primary structure (the peptide bonds) remains intact.
Causes: heat, change of pH (strong acid or base), heavy-metal
ions, organic solvents (ethanol), detergents and ultraviolet
radiation. Familiar examples are the coagulation of egg-white
on heating and the curdling of milk by lemon juice.
[See diagram in the PDF version]
(i) Peptide linkage = amide bond -CO-NH- between two
amino acids. (ii) Primary structure = exact sequence of amino acids in
the polypeptide chain. (iii) Denaturation = loss of protein's native
3-D shape and biological activity, with primary structure preserved.
AP
Aarav Pillai
Ph.D Biochemistry, IISc Bangalore
Verified Expert
Structural angle. Each term sits at one rung of the protein
``structure ladder'': peptide bond (atomic), primary structure
(sequence), denaturation (loss of higher-order folds).
Alternative approach: build a protein ladder in your mind.
Imagine four floors of a building: atomic (peptide bond) →
sequence (primary) → local fold (α-helix, β-sheet =
secondary) → overall fold (tertiary) → assembly of chains
(quaternary). Denaturation collapses floors 2, 3 and 4 but leaves
floor 1 (the steel skeleton, i.e. the peptide bonds) intact. This
analogy makes the three definitions easy to recall together.
Peptide bond. Mechanistically this is a nucleophilic acyl
substitution: the amine -NH2 attacks the carboxyl
-COOH, water leaves, and an amide remains. The carbonyl
C=O and the N-H are coplanar (partial double-bond
character), which fixes the backbone geometry and underlies
α-helix and β-sheet formation.
Primary structure. Spell out the sequence with one-letter
codes: e.g. the first few residues of human insulin's A chain
are Gly-Ile-Val-Glu-Gln. Mutate one of these to a different
amino acid and the protein may no longer fold or function. The
famous sickle-cell mutation is one such single-residue change:
Glu → Val at position 6 of β-haemoglobin.
Denaturation. Heating egg white from 20 ∘C to
70 ∘C converts the soluble globular ovalbumin
into an opaque, insoluble coagulate; the peptide bonds are
still there, but the hydrogen bonds and disulphide bridges
that held the native fold have broken, so the protein no
longer functions.
Concept linkage. Peptide bond - glycosidic bond -
phosphodiester bond is a one-line summary of the three covalent
condensation bonds in this whole chapter, between amino acids
/ sugars / nucleotides respectively. Every chapter question
ultimately turns on these three bond families.
Why this matters. Cooking, pasteurisation, sterilisation by
heat, and the action of acidic gastric juice all rely on the same
chemistry: irreversible denaturation of protein structure without
breaking peptide bonds. The Mediterranean ``ceviche'' (fish cooked in
lemon juice, no heat) is the same chemistry driven by acid instead of
temperature.
Exam-relevance flag. The three-part definition question
(peptide / primary / denaturation) is a 3-mark CBSE staple. Score full
marks by writing one definition per part + one concrete example for
denaturation (egg white coagulation, milk curdling).
(i) Peptide bond -CO-NH-. (ii) Primary structure =
amino-acid sequence. (iii) Denaturation = loss of 3-D fold and
biological function while primary structure is preserved.
Q 10.13
What are the common types of secondary structure of proteins?
Concept used. The secondary structure of a protein
is the regular, repeating spatial arrangement of the polypeptide
backbone in space, stabilised by hydrogen bonding between the
>C=O and the N-H groups of the peptide bonds. Two
common patterns are observed in nature.
α-Helix. The polypeptide is coiled into a
right-handed helix. The >C=O of every amino acid is
hydrogen-bonded to the N-H of the amino acid four
residues ahead in the sequence. Each turn of the helix
contains 3.6 residues and is 0.54 nm in pitch. The side chains
(R) project outward. The α-helix is the
characteristic fold of α-keratin (in hair, wool
and nails) and parts of haemoglobin and myoglobin.
β-Pleated sheet. Two or more nearly fully
extended polypeptide chains lie side by side, held together by
C=O ⋯ H-N hydrogen bonds between adjacent chains.
The backbone takes a zig-zag pleated shape with side chains
alternating above and below the plane. Adjacent strands may
run in the same direction (parallel sheet) or in
opposite directions (antiparallel sheet). The
β-sheet is found in silk fibroin and many
digestive enzymes.
[See diagram in the PDF version]
The two common secondary structures of proteins are the
α-helix and the β-pleated sheet, both
stabilised by hydrogen bonds between >C=O and N-H groups
of the peptide backbone.
KR
Krishna Rao
M.Sc Biochemistry, JNU
Verified Expert
Picture-first angle. A protein's backbone has only a small
number of stable repeating shapes: imagine taking a long chain and
either coiling it into a spring (α-helix) or laying it out flat
in zig-zag rows (β-sheet). All other arrangements are local
turns or random coil.
Alternative approach: identify by length scale. If the
hydrogen-bond distance is along the same chain and the period is 4
residues, you are looking at an α-helix. If the hydrogen bond
links two different chains running side by side, you are looking at a
β-sheet. Question paper diagrams sometimes hide the chain
labels; checking the H-bond direction is the surest way to identify
the motif.
α-Helix: 3.6 residues per turn; pitch 0.54 nm;
C=O of residue i hydrogen-bonds to N-H of
residue i+4. The side chains point outward from the
cylindrical body of the helix. Each helix turn rises 0.54
nm; in a 36-residue helix that is exactly 10 turns and a
height of 5.4 nm.
β-Pleated sheet: extended strands (∼0.35 nm per
residue) run side by side. Hydrogen bonds run perpendicular to
the chain direction. Side chains alternate above and below the
sheet plane. Two flavours: parallel (both chains run
5' → 3' wait - peptides: both chains N → C in
the same direction) and antiparallel (opposite
directions). Antiparallel is more stable because the H-bonds
are geometrically straight.
Each type forms whenever the local sequence has the right
propensity (alanine, leucine, glutamate favour helix; valine,
isoleucine, tyrosine favour sheet). Proline is a famous
helix-breaker because its rigid ring cannot adopt the helical
backbone angle.
Concept linkage. The pattern of regular intramolecular H-bonds
is conceptually the same one you will meet in DNA (Q23), where
the H-bonds form between bases on the two strands of the
double helix. Hydrogen bonding is the universal stabiliser of
biological secondary structure.
Why this matters. Almost every globular protein in the body
is built by combining short stretches of α-helix and
β-sheet, joined by turns. Understanding these two motifs is the
foundation of structural biology and of the AlphaFold protein-folding
revolution that won the 2024 Nobel Prize in Chemistry.
Exam-relevance flag. ``What are the common types of secondary
structure'' is a 2-mark CBSE VSA. Bonus mark for a labelled sketch of
either motif.
The two main secondary structures of proteins are the
α-helix and the β-pleated sheet.
Q 10.14
What type of bonding helps in stabilising the α-helix
structure of proteins?
Concept used. The α-helix is held together by
intramolecular hydrogen bonds between peptide-bond atoms of
the same polypeptide chain.
In the polypeptide backbone every peptide bond contributes a
>C=O group (a hydrogen-bond acceptor) and an N-H
group (a hydrogen-bond donor).
When the chain coils into the α-helix, the >C=O
of residue i comes into line with the N-H of residue
i+4. A hydrogen bond forms:
>C=O ⋯ H-N<.
Each such hydrogen bond is weak (∼20 kJ/mol), but several
thousand of them along a helix add up to a strong cumulative
stabilisation.
These hydrogen bonds run roughly parallel to the helix axis.
The side chains R point outward from the axis and do
not directly stabilise the helix in most cases.
The α-helix of a protein is stabilised by
intramolecular hydrogen bonds between the >C=O of one
peptide bond and the N-H of the peptide bond four amino acids
ahead in the same chain.
SG
Sanya Gupta
M.Sc Biochemistry, IIT Delhi
Verified Expert
Quick reading. ``H-bond'' is the headline answer; everything
else is detail about who donates and who accepts.
Alternative approach: count from the carbonyl. Imagine
walking down the chain starting at the C=O of residue
i. Step forward by four residues. Look at the N-H of residue
i+4. That is the partner. The 4-residue spacing is what generates
the 3.6-residue-per-turn helix; one turn brings the chain back to
the same face of the cylinder.
Donor: amide N-H of residue i+4.
Acceptor: carbonyl >C=O of residue i.
Geometry: bond runs nearly parallel to the helix axis, with
NO distance ∼0.29 nm. The
N-H angle is almost linear (160∘
to 180∘), close to the ideal for hydrogen bonding.
Strength: ∼20 kJ/mol per bond; the helix carries thousands
of them in tandem, so disruption (e.g. by heat or pH change)
unfolds the helix even though each individual bond is weak.
Compare with the ∼350 kJ/mol of a single C-C covalent
bond: H-bonds are about 5% as strong but vastly more abundant
in a folded protein.
Concept linkage. The same logic (∼20 kJ/mol H-bond,
cooperative chains of them) explains the stability of the
β-sheet, of double-stranded DNA, and of liquid water
itself. Hydrogen bonding is the universal sub-covalent ``glue''
of biomolecules.
Why this matters. Hydrogen bonding is the universal stabilising
interaction of every protein's secondary structure, the DNA double
helix, and water itself. Recognising the pattern in the α-helix
sets the template for all of biological hydrogen bonding.
Exam-relevance flag. This is a 1-mark CBSE VSA. Answer in a
single sentence and move on - longer answers waste time.
Intramolecular H-bonds between >C=O (residue i) and
N-H (residue i+4) stabilise the protein α-helix.
Q 10.15
Differentiate between globular and fibrous proteins.
Concept used. Proteins are classified by overall shape into
two families. Globular proteins fold into roughly spherical
shapes by extensive bending of the polypeptide; fibrous
proteins are long, thread-like, often built from parallel chains held
side by side.
Shape and solubility. Globular proteins are spherical and
usually water-soluble; fibrous proteins are
thread-like and insoluble in water.
Bonding pattern. Globular proteins are held by relatively weak
hydrogen bonds plus disulphide bridges that pin folded
regions together; fibrous proteins are stabilised mainly by
strong hydrogen bonds between long parallel chains, sometimes
cross-linked by disulphide bridges (as in keratin).
Biological role. Globular proteins serve dynamic
functions: enzymes, transport, hormones, antibodies (e.g.
insulin, haemoglobin, all enzymes). Fibrous proteins serve
structural functions: connective tissue, hair, skin,
nails (e.g. keratin in hair, collagen in tendons, fibroin in
silk).
Comparison-first angle. Globular and fibrous are the two
``end members'' of protein architecture.
Alternative approach: starting from solubility. A quick way
to classify an unknown protein is its behaviour in water. If it
dissolves → globular; if it stays as fibres or sheets in water
→ fibrous. Why does this work? Globular proteins bury their
hydrophobic side chains in a compact core and expose polar / charged
side chains to water. Fibrous proteins, in contrast, expose
hydrophobic side chains along the fibre's lateral surface, where they
favour stacking with neighbouring fibres rather than wetting with
water.
Look at the chain. If it folds tightly upon itself, hydrophobic
residues inside, polar outside → globular, soluble. Compact
spherical shape with a diameter of just a few nanometers.
If parallel chains stack and hydrogen-bond into long fibres
with hydrophobic side chains buried in the fibre interior →
fibrous, insoluble. These fibres can be metres long (- a single
muscle protein in a giraffe's neck).
Match to function. Mobile (catalysis, signalling, transport,
defence) → globular. Stationary (structure, tensile
strength) → fibrous.
Concept linkage to denaturation (Q18). Heating both classes of
protein destroys their higher-order folds, but the
consequences are different: globular proteins become useless
(the enzyme activity dies); fibrous proteins, often already
biologically inactive, simply lose their mechanical strength
(hair gets brittle, denatures and breaks).
Why this matters. Tendons (collagen, fibrous) and the enzymes
of the blood (globular) both come out of the same twenty amino acids;
only the folding differs. This sums up the elegance of protein
architecture.
Exam-relevance flag. 3-mark CBSE staple; expected items:
shape + solubility + bond type + function + examples. Five rows of
parallel comparison.
How do you explain the amphoteric behaviour of amino acids?
Concept used. A species that can react both as an acid (donate
H+) and as a base (accept H+) is called
amphoteric. Every standard α-amino acid contains both
an acidic carboxyl group (-COOH) and a basic amino group
(-NH2) on the same carbon, so it is intrinsically amphoteric.
In aqueous solution the -COOH group loses a proton to
the -NH2 group of the same molecule, producing a
zwitterion (dipolar ion):
H2N-CHR-COOH <=> +H3N-CHR-COO-.
Because of the zwitterion, amino acids exist mostly as
crystalline ionic solids with high melting points and good
solubility in water.
In an acidic medium (low pH, excess H+) the
-COO- accepts a proton and the amino acid becomes a
cation:
+H3N-CHR-COO- + H+ -> +H3N-CHR-COOH.
Here the amino acid acts as a base.
In a basic medium (high pH, excess OH-) the +NH3
loses a proton and the amino acid becomes an anion:
+H3N-CHR-COO- + OH- -> H2N-CHR-COO- + H2O.
Here the amino acid acts as an acid.
The pH at which the amino acid carries zero net charge is its
isoelectric point (pI). At this pH the molecule
does not migrate in an electric field - a principle used in
protein electrophoresis.
[See diagram in the PDF version]
Amino acids are amphoteric because each molecule carries
both an acidic -COOH and a basic -NH2 group on the same
α-carbon. They exist as zwitterions in neutral aqueous solution,
form cations in acid and anions in base.
SS
Siddharth Singh
M.Sc Chemistry, IIT Bombay
Verified Expert
Structural angle. The amphoteric behaviour follows from the
two functional groups; the zwitterion is what makes the textbook
behaviour observable.
Alternative approach: isoelectric point as a numericalaverage. For a neutral amino acid like glycine with pKa1
= 2.34 (carboxyl) and pKa2 = 9.60 (amine), the
isoelectric point is the average of the two:
pI = 12(pKa1 + pKa2)
= 12(2.34 + 9.60) = 5.97.
At pH 5.97 the molecule carries zero net charge and does not migrate
in an electric field - the principle behind electrophoresis. For
alanine the pI is similar (∼ 6.0); for acidic amino acids
(aspartate, pKa of side chain ∼ 3.9) the pI is much
lower (∼ 2.8); for basic amino acids (lysine, pKa of
side chain ∼ 10.5) the pI is much higher (∼ 9.7).
Identify the two groups: -COOH (pKa ∼2.3, acidic)
and -NH2 (pKa ∼9.6 of +NH3, basic). At
physiological pH (∼7) the carboxyl is fully deprotonated
and the amine is fully protonated; the molecule carries both
charges → zwitterion.
Add acid: -COO- picks up a proton; the amine stays
protonated; net charge +1. The amino acid is a base.
Add base: the -NH3+ loses a proton; the carboxylate
stays; net charge -1. The amino acid is an acid.
Concept linkage. The same two acidic / basic groups create the
N-terminus and C-terminus of every protein; in a folded
protein, the N-terminus is protonated and the C-terminus is
deprotonated under physiological pH, mirroring the zwitterion
story at the chain level.
Why this matters. Because amino acids buffer near pH 7 and
near the pI, blood and intracellular fluid use amino-acid/protein
zwitterions as part of their buffering system. The zwitterion is also
why amino acids are crystalline solids with very high melting points
- the crystal is held together by electrostatic attractions between
+ and - centres, like a tiny ionic lattice.
Exam-relevance flag. 3-mark CBSE asks ``explain amphoteric
behaviour'' with the equation of zwitterion formation as the central
chemistry. Include both equilibria (acid side, base side) and the
sketch of cation zwitterion
anion.
Two opposite functional groups on one carbon (acidic
-COOH, basic -NH2) plus a zwitterionic form make every
amino acid amphoteric.
Q 10.17
What are enzymes?
Concept used.Enzymes are the protein biocatalysts
of living systems. They are essentially globular proteins (a few are
catalytic RNA molecules called ribozymes, but the standard textbook
definition covers proteins). Like any catalyst, an enzyme accelerates
a reaction without being consumed and without changing the position of
equilibrium.
Chemical identity. Each enzyme is a protein (or in some cases
a protein associated with a small cofactor or coenzyme). The
polypeptide chain folds into a precise 3-D shape with a small
cavity, the active site, into which the substrate
fits.
Catalytic property. Enzymes lower the activation energyEa of a biological reaction by many orders of magnitude, so
the reaction proceeds many millions of times faster than the
same reaction in the test tube at body temperature.
Specificity. Each enzyme catalyses essentially one reaction
on one substrate (or one class of related substrates). The
``lock and key'' fit between the active site and the substrate
explains this specificity.
Naming. Enzymes are usually named by adding the suffix
-ase to the name of the substrate or reaction:
maltase hydrolyses maltose; lipase hydrolyses
lipids; lactate dehydrogenase dehydrogenates lactate.
Some classical names persist: pepsin, trypsin.
[See diagram in the PDF version]
Enzymes are highly specific globular-protein biocatalysts
that speed up biological reactions by lowering the activation energy,
without being consumed and without changing the equilibrium.
NK
Neha Kumar
M.Sc Biochemistry, AIIMS Delhi
Verified Expert
Strategic angle. Three properties together pin down what an
enzyme is: protein nature, catalytic action, and high specificity.
Alternative approach: lock-and-key vs induced-fit models. Two
models describe how the substrate binds the active site. Lock
and key (Fischer, 1894): a rigid active site whose shape exactly
fits the substrate. Induced fit (Koshland, 1958): a flexible
active site that re-shapes around the substrate as it binds, like a
hand closing on a ball. The induced-fit model is closer to reality,
but the lock-and-key picture is enough to explain enzyme specificity
in Class 12.
Chemical: protein (almost always). Three-dimensional folding
creates an active site with a precise size and chemical
environment. A few enzymes (ribozymes) are RNA molecules
rather than proteins, but those are an exception.
Functional: catalyst - lowers Ea, unchanged at the end of
the reaction, does not shift equilibrium, but reaches it much
faster. Enzymes can speed up a reaction by factors of 106
to 1017.
Discriminating: highly substrate- and reaction-specific.
Maltase splits maltose but not sucrose; sucrase does the
reverse. Two related but distinct sugars need two distinct
enzymes.
Concept linkage. Enzymes themselves are proteins (Q12–Q15);
proteins are polymers of amino acids (Q11–Q16); amino acids
derive their reactivity from the zwitterionic form (Q16);
nucleic acids encode the sequence of every enzyme (Q21–Q25).
Q17 is a hub connecting the carbohydrate / protein / nucleic-acid
threads of this chapter.
Why this matters. Without enzymes the chemistry of life would
run too slowly to sustain growth and reproduction at 37 ∘C;
every metabolic pathway - glycolysis, the citric acid cycle, DNA
replication - depends entirely on enzyme catalysis.
Exam-relevance flag. ``What are enzymes? Give two examples''
is asked as a 2-mark CBSE VSA almost every year. State the
nature-action-specificity triad + two examples (maltase, urease).
Enzymes are protein biocatalysts: they speed up specific
biochemical reactions by lowering activation energy.
Q 10.18
What is the effect of denaturation on the structure of proteins?
Concept used.Denaturation of a protein is the
process in which the native three-dimensional shape of the protein is
destroyed by heat, change of pH, organic solvents, heavy-metal ions,
detergents or ultraviolet radiation, leaving the polypeptide chain
unable to perform its biological function. The peptide bonds (i.e. the
primary structure) are not broken in denaturation.
Primary structure (the sequence of amino acids) remains
unchanged because peptide bonds are covalent and are
not affected by mild heat or pH changes.
Secondary structure (the regular α-helix or β-sheet
hydrogen-bond pattern) is disrupted: heat or pH change
breaks the weak hydrogen bonds.
Tertiary structure (the overall 3-D fold, held by hydrogen
bonds, disulphide bridges, hydrophobic effects and electrostatic
attractions) is destroyed.
Quaternary structure (the way different polypeptide subunits
assemble) also disintegrates.
Consequence. The protein loses its biological activity:
enzymes can no longer catalyse, antibodies can no longer bind
antigen, haemoglobin can no longer carry oxygen. Familiar
observations - coagulation of egg-white on boiling, curdling
of milk by lemon juice - are everyday examples of denaturation.
[See diagram in the PDF version]
Denaturation destroys the secondary, tertiary and quaternary
structures of a protein (i.e. the 3-D fold), while leaving the
primary structure (the peptide bonds) intact. The protein loses its
biological activity.
AP
Aditi Patel
Ph.D Biochemistry, IISc Bangalore
Verified Expert
Quick reading. Denaturation is the reversible (sometimes
irreversible) unfolding of a protein. It is structural, not chemical
in the peptide-bond sense.
Alternative approach: list of denaturing agents. Memorise
the standard list: heat, strong acid or base, heavy metals
(Hg2+, Pb2+, Ag+), organic solvents (ethanol,
acetone), detergents (SDS), UV / ionising radiation, mechanical
shaking. For each agent, name one everyday example (heat →
boiling eggs, acid → curdling milk, heavy metal → Pb-poisoning
of enzymes, organic solvent → surgical alcohol).
Heat. Boiling breaks H-bonds and disulphide bridges →
ovalbumin in egg-white coagulates. The change is irreversible
because the fold cannot find its way back to the native state
once entangled.
Strong acid or base. Charged side chains repel or attract
differently → the fold collapses (milk curdles when lemon
juice lowers pH below the isoelectric point of casein,
∼4.6).
Heavy metals (Hg2+, Pb2+) and organic solvents
bind to or strip away water from key residues →
precipitation. Surgeons use 70% ethanol exactly because it
denatures (and so destroys) the proteins of bacteria. Mercury
and lead poisoning kill enzymes by binding cysteine -SH
groups, breaking the disulphide bridges.
In every case the primary structure (peptide bonds) is intact;
only the folded 3-D shape and biological activity are lost.
Add urea or guanidinium chloride to a denatured protein
solution and the chains will refold to the native state if the
primary structure is short and simple (the Anfinsen experiment
on ribonuclease, 1961 Nobel Prize).
Concept linkage. Denaturation is the structural counterpart of
enzyme inhibition (Q17). An inhibitor blocks the active
site without changing the fold; denaturation destroys the
fold. Both end the enzyme's catalytic activity, but via
different chemistries.
Why this matters. Cooking, sterilisation, gastric digestion
and the action of antiseptics all rely on the same idea: change the
environment, destroy the fold, kill the function.
Exam-relevance flag. 3-mark CBSE asks ``State the effect of
denaturation on the structure of a protein''. Expected answer:
secondary, tertiary, quaternary structures are destroyed; primary
structure is preserved; activity is lost.
Denaturation: secondary, tertiary and quaternary structures
collapse; primary structure (peptide bonds) survives; protein loses
biological activity.
Q 10.19
How are vitamins classified? Name the vitamin responsible
for the coagulation of blood.
Concept used.Vitamins are organic compounds
required in small amounts by the body for normal growth and metabolic
function; the body cannot synthesise most of them in adequate amounts,
so they must come from the diet. They are classified by solubility.
Classification by solubility.
Fat-soluble vitamins: A, D, E and K. They
dissolve in fat and oils, are stored in the liver and
in fat depots, and need bile salts for absorption.
Excessive intake can be toxic because the body stores
rather than excretes them.
Water-soluble vitamins: the B group
(B1 thiamine, B2 riboflavin,
B3 niacin, B5 pantothenic acid,
B6 pyridoxine, B7 biotin, B9
folic acid, B12 cobalamin) and vitamin C
(ascorbic acid). They dissolve in water and are not
stored to any large extent; the excess is excreted in
urine, so they must be supplied regularly. Vitamin
B12 is an exception that is stored in
liver.
Coagulation of blood. The vitamin essential for normal blood
clotting is Vitamin K (named from the German
Koagulation). It is a fat-soluble vitamin and acts as
a cofactor in the carboxylation of glutamate residues of
certain clotting-factor proteins (II, VII, IX, X).
[See diagram in the PDF version]
Vitamins are classified by solubility as fat-soluble
(A, D, E, K) and water-soluble (B-group, C). The vitamin
responsible for blood coagulation is Vitamin K.
DJ
Dev Joshi
M.Sc Biotechnology, AIIMS Delhi
Verified Expert
Definition-first angle. Two questions in one: how to group
vitamins and which one helps blood clot.
Alternative approach: classification by storage in the body.
A second valid classification is ``stored'' vs ``not stored''.
Fat-soluble vitamins are stored in liver and adipose tissue, so
overdosing is possible (hypervitaminosis A or D). Water-soluble
vitamins (except B12) are not stored and excess is
excreted in urine, so daily intake is required and overdose is rare.
This second classification matches the first almost perfectly and
helps you justify why fat-soluble vitamins are toxic at high doses.
Group by solubility. Fat-soluble (A, D, E, K) dissolve in
lipids and need bile salts for absorption. Water-soluble
(B-complex, C) dissolve in water and travel freely in plasma.
Vitamin K is the clotting vitamin: it lets the liver carry out
the post-translational γ-carboxylation of glutamic-acid
residues on prothrombin, without which the clotting cascade
cannot run.
Sources of vitamin K: green leafy vegetables, eggs, liver and
bacterial synthesis in the gut.
Numerical / quantitative note. The recommended daily allowance
(RDA) of vitamin K is around 90–120 μg per day for adults.
A 100 g serving of spinach contains ∼500 μg, more
than enough.
Concept linkage. Vitamins act as enzyme cofactors - they are
the small molecules that turn an inactive apoenzyme into an
active holoenzyme. So Q19 plugs directly into Q17 (enzymes).
Why this matters. Newborns receive an injection of vitamin K
to avoid haemorrhagic disease of the newborn; people on blood thinners
like warfarin must keep vitamin K intake steady because warfarin
blocks vitamin-K recycling.
Exam-relevance flag. 2-mark CBSE asks ``How are vitamins
classified? Name the vitamin for blood clotting.'' Two clean lines:
classification by solubility + ``vitamin K''. Don't lose marks by
forgetting the second part.
Fat-soluble (A, D, E, K) vs water-soluble (B-group, C).
Vitamin K is essential for blood clotting.
Q 10.20
Why are vitamin A and vitamin C essential to us?
Give their important sources.
Concept used. Vitamins serve very specific biochemical roles.
Knowing the role of each vitamin makes it easy to remember the
deficiency disease that results from its absence.
Vitamin A (retinol).
Function: it is essential for the synthesis of
rhodopsin (the visual pigment of the rods of the
retina) and for the maintenance of healthy epithelial
tissue and skin.
Deficiency disease: night blindness (loss of
ability to see in dim light) and xerophthalmia
(drying of the cornea).
Function: it is required for the hydroxylation of
proline and lysine residues during collagen
synthesis, for the absorption of iron from the gut
and as a water-soluble antioxidant.
Deficiency disease: scurvy (bleeding gums,
loose teeth, slow wound healing, joint pain) because
collagen cannot be properly cross-linked.
Sources: citrus fruits (lemon, orange, lime), amla
(Indian gooseberry - very rich), guava, green chilli,
tomato, fresh leafy vegetables.
Vitamin A is essential for vision and healthy
epithelium; deficiency causes night blindness. Sources: carrots,
spinach, milk, butter, egg yolk, fish-liver oil. Vitamin C is essential for collagen synthesis, iron
absorption and antioxidant defence; deficiency causes scurvy. Sources:
citrus fruits, amla, guava, tomato.
RC
Riya Chatterjee
M.Sc Biochemistry, JNU
Verified Expert
Function-first angle. Match each vitamin to the
molecule it makes possible.
Alternative approach: pair each vitamin with its named
disease. The shortest mnemonic in this chapter is ``A is for
anti-night-blindness; C is for collagen / scurvy;
D is for deficient bones (rickets); K is for klotting
(coagulation); B1 is for the (b)beri-beri'' and so on. Going
down this list of disease names is the quickest way to identify a
vitamin from a question stem.
Vitamin A. Reacts (as 11-cis-retinal) with the protein opsin
to give rhodopsin; light isomerises the chromophore and
triggers the visual signal. Without vitamin A, rods cannot
regenerate rhodopsin → night blindness. Chronic deficiency
progresses to xerophthalmia (corneal dryness) and total
blindness - still a leading cause of preventable childhood
blindness in poor countries.
Vitamin C. Co-substrate for prolyl- and lysyl-hydroxylase
enzymes that hydroxylate residues in pre-collagen. Without
vitamin C, collagen helices do not cross-link → scurvy
(weak blood-vessel walls, bleeding gums). Also acts as a
water-soluble antioxidant and as a co-factor for iron
absorption.
Sources, easy to remember: ``orange-coloured = A'' (carrot,
papaya, mango) and ``sour citrus = C'' (lemon, amla, orange).
Amla is by far the richest natural source of vitamin C in
India (∼600 mg per 100 g) - ten times that of orange.
Concept linkage. Both vitamin A and vitamin C are involved in
enzyme cofactor chemistry (Q17) and protein chemistry (Q12);
A is part of rhodopsin (a protein-cofactor complex), and C
helps modify collagen (a fibrous protein) post-translationally.
Why this matters. Two simple molecules sit at the heart of
two major bodily systems (vision and connective tissue). Deficiency
of either causes a disease named in textbooks for two hundred years.
Exam-relevance flag. 3-mark CBSE staple: ``Why are vitamins A
and C essential to us? Give their important sources.'' Marker
expects: function + deficiency + sources for each vitamin = 6 sub-items.
Vitamin A: needed for vision and epithelial health (sources:
carrots, spinach, butter, fish-liver oil). Vitamin C: needed for
collagen synthesis and iron absorption (sources: citrus fruits, amla,
guava).
Q 10.21
What are nucleic acids? Mention their two important functions.
Concept used.Nucleic acids are long-chain
biopolymers built from monomer units called nucleotides. There
are two classes: deoxyribonucleic acid (DNA) and
ribonucleic acid (RNA).
Building block. A nucleotide consists of three
chemical pieces:
a pentose sugar (2-deoxyribose in DNA, ribose in RNA);
a nitrogenous base (adenine A, guanine G, cytosine C
and either thymine T in DNA or uracil U in RNA);
a phosphate group -O-PO(OH)2.
Nucleotides are joined through phosphodiester bonds between
the 3'-OH of one sugar and the 5'-phosphate of the next,
producing a sugar-phosphate backbone with bases projecting
sideways.
Functions of nucleic acids (two main ones).
Storage and transfer of genetic information.
DNA stores the complete genetic blueprint of an
organism; it is copied (replication) and passed to
daughter cells, ensuring heredity.
Protein synthesis. The information stored in
DNA is transcribed into messenger RNA (mRNA) and then
translated by ribosomal RNA (rRNA) and transfer RNA
(tRNA) into specific proteins. This is the central
dogma of molecular biology: DNA → RNA →
protein.
[See diagram in the PDF version]
Nucleic acids are biopolymers of nucleotides (sugar + base +
phosphate). Two main functions: (i) storage and transmission of
genetic information (DNA), and (ii) protein synthesis (mRNA, rRNA,
tRNA).
AS
Ankit Sharma
Ph.D Molecular Biology, NCBS Bangalore
Verified Expert
Strategic angle. Define the polymer, then state what it does.
Alternative approach: information vs machinery. A nucleic
acid is fundamentally an information molecule. Compare with
proteins (machines), carbohydrates (fuel and scaffolding) and lipids
(membranes and signals). Of all four biomolecule classes, only the
nucleic acids carry sequence-encoded information. This single
observation answers ``why two functions of nucleic acids'' in one
line: store the information (DNA) and read out the information (RNA
→ protein synthesis).
Polymer: chain of nucleotides linked through 3',5'-
phosphodiester bonds; the order of bases along the chain is the
``information''.
Each nucleotide carries three parts (pentose sugar + base +
phosphate); the sequence of bases is the variable that
encodes meaning. The four-letter alphabet (A, G, C, T/U) is
enough because biology translates triplets of bases (codons)
into the 20-letter alphabet of amino acids.
Two functions (in shortest form):
DNA holds the genetic blueprint and is duplicated at
each cell division so the information is preserved.
Semiconservative replication ensures that each
daughter cell receives an identical copy.
RNA species (mRNA, tRNA, rRNA) take that information
from the nucleus and translate it into the proteins
that actually do the work in the cell.
Concept linkage to the chapter map. Carbohydrates → joined
by glycosidic bonds; proteins → joined by peptide bonds;
nucleic acids → joined by phosphodiester bonds. The whole
chapter resolves into three condensation polymers each
identified by its own characteristic bond.
Why this matters. Every inherited feature of an organism, and
every protein it can make, is encoded in its nucleic acids. This is
the basis of modern genetics, biotechnology and medicine - from PCR
testing to gene therapy to mRNA vaccines.
Exam-relevance flag. 2-mark CBSE asks for ``two functions''.
Don't list four or five; the marker wants exactly two. Storage
(replication) and expression (transcription + translation) are the two
to write.
Nucleic acids = polymers of nucleotides. Two functions:
storage of genetic information (DNA) and protein synthesis (RNA).
Q 10.22
What is the difference between a nucleoside and a nucleotide?
Concept used. A nucleoside and a nucleotide are the
fundamental building blocks of nucleic acids. The difference is the
presence or absence of a phosphate group.
Nucleoside. A nucleoside is the compound formed by
the attachment of a nitrogenous base to the 1'-carbon of a
pentose sugar (ribose in RNA, 2-deoxyribose in DNA) through an
N-glycosidic linkage. It contains only two components:
base + sugar.
Nucleoside = Base + Sugar.
Examples: adenosine (adenine + ribose), guanosine (guanine +
ribose), cytidine (cytosine + ribose), uridine (uracil +
ribose), thymidine (thymine + 2-deoxyribose).
Nucleotide. A nucleotide is a nucleoside in which the
5'-OH of the sugar is esterified with phosphoric acid. It
contains three components: base + sugar +
phosphate.
Nucleotide = Base + Sugar +
Phosphate.
Examples: adenosine monophosphate (AMP), guanosine monophosphate
(GMP), cytidine monophosphate (CMP). Adding two more phosphates
gives ADP and ATP, the energy currency of the cell.
Polymer relationship. Nucleotides are the actual monomers of
DNA and RNA, joined through phosphodiester bonds between the
3'-OH of one sugar and the 5'-phosphate of the next.
Nucleosides cannot polymerise on their own - they need the
phosphate.
[See diagram in the PDF version]
Nucleoside = base + sugar.
Nucleotide = base + sugar + phosphate.
Nucleotides are the monomers of DNA and RNA.
KN
Kavya Nair
M.Sc Biotechnology, AIIMS Delhi
Verified Expert
Quick reading. The difference is the phosphate.
Alternative approach: trace the bond types. A nucleoside has
exactly one covalent bond between its two pieces: the N-glycosidic
bond between C-1' of the sugar and the nitrogen of the base. A
nucleotide adds a second bond: a phosphoester bond between the
5'-OH of the sugar and the phosphate. Counting bonds is a quick
structural way to tell the two apart.
Nucleoside: an N-glycoside of a base with a pentose sugar.
Example: adenosine = adenine + ribose. The base is attached to
C-1' of the sugar; no phosphate.
Nucleotide: the 5'-phosphate ester of a nucleoside. Example:
AMP = adenine + ribose + phosphate. Nucleotides can carry one,
two or three phosphate groups (AMP, ADP, ATP). The extra
phosphates store metabolic energy in the P-O-P anhydride bonds.
Biological consequence. Free nucleotides (ATP, GTP, NADH,
FADH2) act as energy carriers and cofactors. Polymerised
nucleotides build DNA and RNA.
Concept linkage to Q21. Only nucleotides - not nucleosides -
can polymerise into nucleic acids because the polymerisation
is a phosphodiester condensation: each new monomer adds its
own phosphate. Nucleosides need to be ``activated'' to the
triphosphate before being added.
Why this matters. Every biochemistry exam asks for this
distinction. Remembering ``phosphate makes the difference'' fixes the
two definitions instantly.
Exam-relevance flag. 2-mark CBSE asks ``Differentiate between
a nucleoside and a nucleotide / give one example of each''. Three
lines suffice: the two definitions + one example pair (adenosine vs
AMP).
Nucleoside = base + sugar; nucleotide = base + sugar +
phosphate.
Q 10.23
The two strands in DNA are not identical but are
complementary. Explain.
Concept used. A DNA molecule consists of two
polynucleotide strands wound round each other in a right-handed
double helix (Watson and Crick, 1953). The two strands are
held together by hydrogen bonds between specific base pairs, and the
rule that controls which base pairs with which is called
Chargaff's base-pairing rule.
State the pairing rule.
Adenine (A, a purine) always pairs with Thymine (T, a
pyrimidine) by two hydrogen bonds.
Guanine (G, a purine) always pairs with Cytosine (C, a
pyrimidine) by three hydrogen bonds.
Symbolically: A = T (2 H-bonds), G
≡ C (3 H-bonds). A purine pairs only with a
pyrimidine, so the diameter of the helix stays constant.
Therefore the two strands are not identical. If one strand
reads 5'-A T G C C G T-3', the other strand must read
3'-T A C G G C A-5'. The sequences are different.
However, the two sequences are complementary: given one
strand, the other is fully determined by the A-T and G-C
rule. The strands also run antiparallel: one runs
5' → 3' while the other runs 3' → 5'.
Consequence. Because of complementarity, each strand carries
all the information needed to reconstruct the other. This is
the basis of the semiconservative replication of DNA:
the strands separate, each acts as a template, and two
identical daughter helices are produced.
[See diagram in the PDF version]
The two DNA strands are not identical in their base sequence,
but each base on one strand has its specific complementary partner on
the other (A with T, G with C). The strands are therefore
complementary and run antiparallel, which is why one strand
fully determines the other.
RV
Rahul Verma
Ph.D Molecular Biology, NCBS Bangalore
Verified Expert
Structural angle. Two strands, antiparallel, glued by
specific H-bonds.
Alternative approach: think of the two strands as a key and
its imprint. If one strand is the key, the other is a mould of the
key. The two are not identical (a key and its mould are mirror
opposites), but each carries all the information needed to reproduce
the other - that is the definition of complementarity. This
analogy carries over directly to PCR and to semiconservative DNA
replication, where each parent strand templates a new daughter
strand.
Strand orientation. One strand 5' → 3' paired with the
other 3' → 5'. The sugar-phosphate backbones are on the
outside; the bases project inward. The two backbones spiral
round each other in a right-handed double helix of diameter
2 nm, with 10 base pairs per turn (3.4 nm per turn).
Specific pairing.
A (purine) with T (pyrimidine) via 2 H-bonds.
G (purine) with C (pyrimidine) via 3 H-bonds.
Always purine + pyrimidine - this keeps the helix diameter
constant at 2 nm.
Complementarity in numbers. Chargaff's rule:
% A = % T and % G = % C
in every DNA, regardless of source. Numerical example: if
human DNA has 30% A, it must have 30% T, leaving 40%
between G and C (i.e. 20% G + 20% C). This is a classic
2-mark Exemplar numerical.
Replication uses complementarity: split, copy each strand,
produce two identical daughter helices. The process is called
semiconservative because each daughter helix retains
one parental strand.
Concept linkage. The A-T and G-C H-bond pattern is just the
nucleic-acid version of the same hydrogen-bond chemistry that
stabilises the α-helix (Q13–Q14). Two H-bonds vs three
H-bonds is also why GC-rich DNA has a higher melting
temperature than AT-rich DNA.
Why this matters. Complementarity underlies PCR, gene
sequencing, mRNA processing and the very idea of inheritance. It is
the most important geometric idea in biology.
Exam-relevance flag. 3-mark CBSE asks ``Why are the two
strands of DNA called complementary?'' Marker expects: A-T / G-C
pairing rule + antiparallel orientation + Chargaff's rule statement.
DNA strands are different in sequence but each base pairs
specifically with its partner (A–T, G–C); they are complementary
and antiparallel.
Q 10.24
Write the important structural and functional differences
between DNA and RNA.
Concept used. DNA and RNA differ in three structural
features (sugar, bases, strandedness) and one main functional
emphasis (storage vs expression of information).
Sugar. DNA contains 2-deoxyribose (no -OH at
C-2). RNA contains ribose (-OH at C-2). The missing
-OH makes DNA chemically more stable than RNA.
Pyrimidine bases. DNA contains the bases A, G, C and
T (thymine). RNA contains A, G, C and U (uracil)
instead of thymine. Thymine differs from uracil by an extra
-CH3 group.
Strandedness and size. DNA is normally double-stranded,
present as a long right-handed helix; the molecule can be
millions of base pairs long. RNA is normally single-stranded,
short to medium in length, and often folded into local
secondary structure (loops, stems).
Location and stability. DNA lives almost entirely in the
nucleus (and in mitochondria/chloroplasts); it is replicated
but not normally degraded. RNA is synthesised in the nucleus
but functions mostly in the cytoplasm; it is short-lived.
Functional roles.
DNA: stores hereditary information and transmits
it from parent to daughter cells by replication.
RNA: expresses the information. mRNA carries
the genetic message from DNA to the ribosome; tRNA
brings the right amino acid; rRNA forms the catalytic
core of the ribosome.
Comparison-first angle. Three structural differences plus one
functional one.
Sugar: deoxyribose vs ribose.
Bases: T (DNA) vs U (RNA).
Strands: double vs single.
Function: master copy (DNA) vs working copy (RNA).
Why this matters. The double-stranded, deoxy form is built
for safe long-term storage; the single-stranded ribo form is built for
quick, disposable use. Evolution kept both for a reason.
What are the different types of RNA found in the cell?
Concept used. The cell contains three principal types of
RNA, each devoted to a particular step in the synthesis of
proteins from genetic information. All three are single-stranded
polymers of ribose nucleotides containing the bases A, G, C and U.
Messenger RNA (mRNA).
Synthesised in the nucleus by transcription of one strand of
the DNA double helix. It carries the genetic message from the
nucleus to the cytoplasm, where it is read three bases at a
time (each triplet is a codon) by the ribosome. The
order of codons in mRNA dictates the order of amino acids in
the protein.
Ribosomal RNA (rRNA).
rRNA is a structural and catalytic component of the
ribosome, the molecular machine on which proteins are
actually built. About 80% of the cell's total RNA is rRNA. It
forms, together with ribosomal proteins, the large and small
subunits of the ribosome.
Transfer RNA (tRNA).
A small RNA (∼70–90 nucleotides) folded into a
clover-leaf shape. Each tRNA carries one specific amino acid
at one end and has a triplet anticodon loop at the
other end. During translation it reads the codon on mRNA and
delivers the corresponding amino acid to the growing
polypeptide.
[See diagram in the PDF version]
Three principal types of RNA: messenger RNA (mRNA),
ribosomal RNA (rRNA) and transfer RNA (tRNA); they
work together to translate the genetic message stored in DNA into
specific proteins.
AD
Arjun Desai
Ph.D Molecular Biology, NCBS Bangalore
Verified Expert
Role-first angle. Three RNAs, three jobs.
mRNA = the blueprint. Length varies with the gene; codons
(groups of three bases) read in sequence.
rRNA = the factory. Combines with proteins to form ribosomes;
catalyses peptide-bond formation through its peptidyl
transferase activity (a ribozyme).
tRNA = the delivery van. One specific amino acid covalently
attached at the 3' end; an anticodon at the loop that
recognises the matching codon on mRNA.
Why this matters. The discovery that rRNA itself catalyses
peptide-bond formation (rather than ribosomal proteins) was a major
piece of evidence that life could have begun in an ``RNA world'' where
RNA both stored information and catalysed reactions.
Three RNAs: mRNA (carries the genetic message), rRNA
(structural component of ribosomes), tRNA (carries amino acids).
Biomolecules Class 12 Chemistry NCERT Solutions FAQs
Ques. Where can I download Biomolecules Class 12 Chemistry NCERT Solutions PDF?
Ans. You can download the Biomolecules Class 12 Chemistry NCERT Solutions PDF directly from this page. Both the Normal and HD versions are available, and both are free.
Ques. How many questions are there in NCERT Class 12 Chemistry Chapter 10 Biomolecules?
Ans. The main exercise of Chapter 10 contains 24 questions, supplemented by 10 intext questions distributed across the chapter body. All 34 questions are solved step-by-step in the Collegedunia PDF on this page.
Ques. Is Biomolecules Chapter 10 part of the 2026-27 syllabus?
Ans. Yes. Chapter 10 Biomolecules is fully retained in the current 2026-27 NCERT print, with the four pillar topics (carbohydrates, proteins, nucleic acids, vitamins) intact. The detailed hormone classification sub-section has been trimmed in the new edition, but the rest of the chapter is unchanged.
Ques. How many pages is the Class 12th Chemistry Biomolecules Solutions PDF?
Ans. The Solutions PDF runs approximately 26 pages and covers all 24 exercise questions plus the 10 intext questions, with structural diagrams of glucose, sucrose, maltose, amino acids, and the DNA double helix drawn in full.
Ques. Why is sucrose a non-reducing sugar?
Ans. In sucrose, the C1 anomeric -OH of alpha-D-glucose and the C2 anomeric -OH of beta-D-fructose are both engaged in the alpha-1,beta-2 glycosidic linkage. With no free anomeric carbon available, sucrose cannot open into its open-chain aldehyde or ketone form and therefore cannot reduce Fehling's or Tollens' reagent.
Ques. What is the difference between DNA and RNA?
Ans. DNA contains deoxyribose sugar, the base thymine, and exists as a double helix. RNA contains ribose sugar, the base uracil (in place of thymine), and is normally single-stranded. DNA stores genetic information; RNA carries the information from DNA to the ribosome for protein synthesis.
Ques. What are essential and non-essential amino acids?
Ans. Essential amino acids cannot be synthesised by the human body and must be obtained from food. There are nine essential amino acids: valine, leucine, isoleucine, threonine, methionine, phenylalanine, tryptophan, lysine, and histidine. Non-essential amino acids can be synthesised by the body from other precursors.
Ques. How do I prepare Biomolecules in 2 days for CBSE Class 12 Chemistry?
Ans. Day 1: memorise the eight differentiation pairs (starch vs cellulose, DNA vs RNA, alpha-helix vs beta-pleated sheet, essential vs non-essential amino acids, glucose vs fructose, globular vs fibrous protein, Vitamin A vs Vitamin C, reducing vs non-reducing). Day 2: revise glucose reactions (acetylation, oxidation with HNO3, reduction with HI), the four protein structure levels, and the vitamin classification table. Then attempt the 24 exercise questions from the Collegedunia PDF.
Ques. What is mutarotation and how is it related to the alpha and beta anomers of glucose?
Ans. Mutarotation is the gradual change in optical rotation when a pure anomer of a reducing sugar is dissolved in water and equilibrates with the other anomer through the open-chain form. For glucose, pure alpha-D-glucopyranose has a specific rotation of +112 degrees and pure beta-D-glucopyranose has +19 degrees; both equilibrate via the open-chain aldehyde to give the equilibrium rotation of +52.5 degrees. Anomers are pairs of stereoisomers that differ only at the anomeric carbon (C1 in glucose), formed because cyclisation creates a new chiral centre. Do not confuse anomers with epimers (differ at one non-anomeric chiral carbon, e.g. glucose vs galactose at C4).
Ques. What is the difference between a nucleoside and a nucleotide?
Ans. A nucleoside is a nitrogen base joined to a pentose sugar (base + sugar; no phosphate) - the linkage is an N-glycosidic bond at the C1' of the sugar. A nucleotide is a nucleoside with a phosphate group added (base + sugar + phosphate); the phosphate is esterified to the C5' of the sugar. Nucleotides are the building blocks of nucleic acids - they polymerise through 5' to 3' phosphodiester linkages to give DNA or RNA. Mnemonic: nucleoside = NO-side (no phosphate); nucleotide = tide of phosphate. Examples - adenosine is a nucleoside; AMP (adenosine monophosphate) is a nucleotide.
Ques. What is the zwitterion form of an amino acid and what is the isoelectric point?
Ans. Amino acids carry both an acidic -COOH and a basic -NH2 on the same molecule. In aqueous solution the -COOH transfers its proton to the -NH2 on the same molecule to give the doubly-charged dipolar form +H3N-CHR-COO-, called the zwitterion. The net charge of the zwitterion is zero; the molecule is electrically neutral overall but carries internal positive and negative charges, which is why amino acids show unusually high melting points and high water solubility. The isoelectric point (pI) is the pH at which the molecule exists predominantly as the zwitterion and shows zero net charge; for a neutral amino acid pI = (pKa1 + pKa2)/2.
Ques. Why is haemoglobin a good example of quaternary protein structure?
Ans. Quaternary structure is the assembly of two or more polypeptide chains held together by non-covalent interactions and disulphide bridges. Haemoglobin is the canonical NCERT example because it is built from four polypeptide subunits - two alpha chains (141 residues each) and two beta chains (146 residues each) - each cradling a heme group with an iron(II) centre. The four subunits cooperate when binding O2: binding at one heme increases the affinity of the others (positive cooperativity), and this is what gives haemoglobin its sigmoidal oxygen-binding curve, which myoglobin (a tertiary-only protein) lacks. Total molecular mass is about 64,500 u.
Ques. Which vitamin causes scurvy and which causes pernicious anaemia?
Ans.Vitamin C (ascorbic acid), a water-soluble vitamin found in citrus fruits, amla and leafy vegetables, prevents scurvy - the deficiency disease that causes bleeding gums, loose teeth, slow wound healing and skin lesions. Vitamin B12 (cobalamin), another water-soluble vitamin (uniquely stored in the liver), prevents pernicious anaemia - a megaloblastic anaemia caused by impaired red blood cell maturation. Note the NCERT marking-scheme distinction: B1 (thiamine) deficiency causes beri-beri, not pernicious anaemia.




























































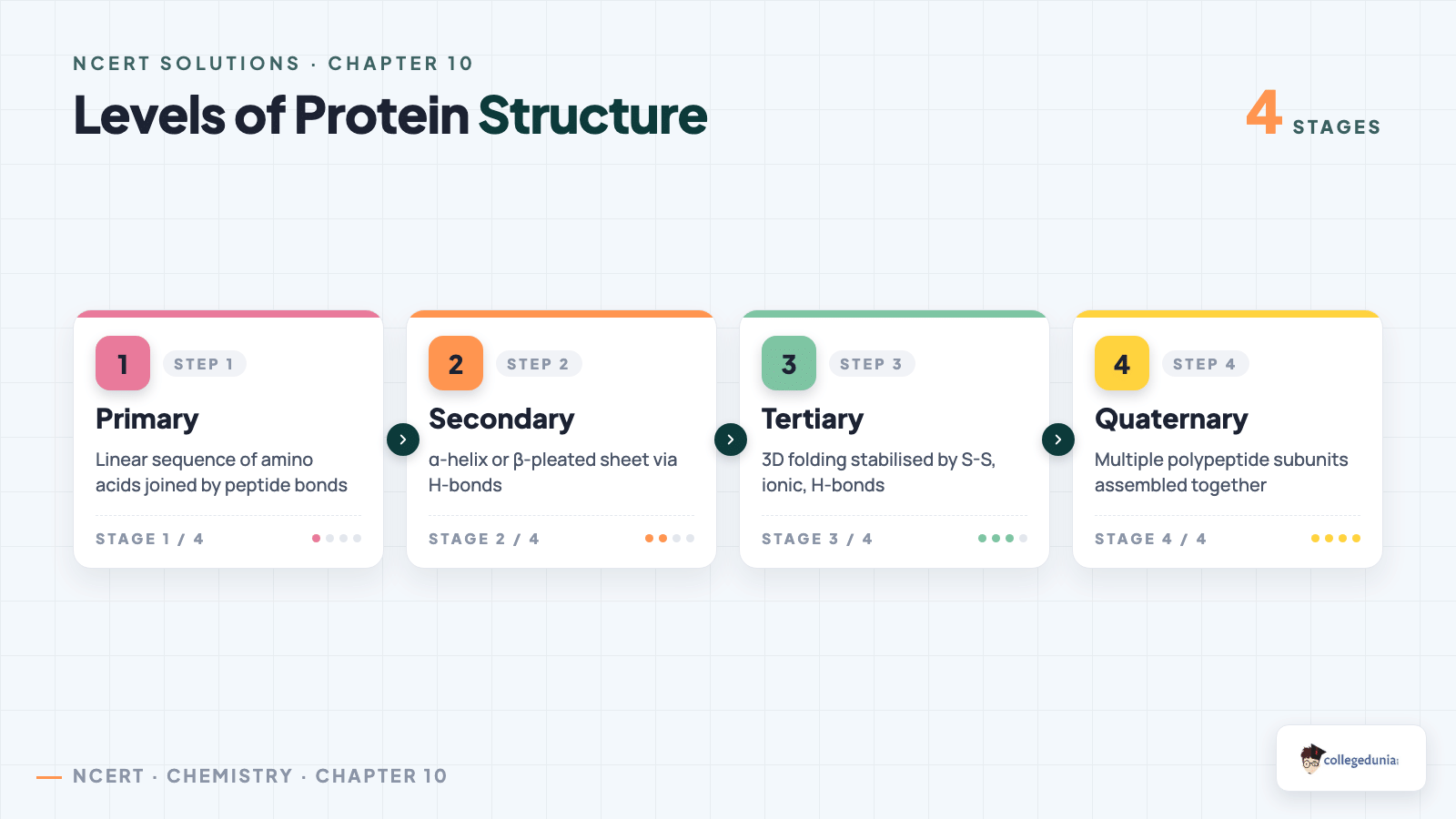



Comments